If the “unicity of corresponding chunking” theorem holds (which seems fairly obvious to me, though I lack the formality to prove it), then this also holds:
- C(A + B) = C(A + C(B)) \geq A + C(B)
- C(A + B) = C(C(A) + B) \geq C(A) + B
If the “unicity of corresponding chunking” theorem holds (which seems fairly obvious to me, though I lack the formality to prove it), then this also holds:
Oh, this gets easier if you split C into two steps: one to raise List Tx into List (List Tx) (by putting every element in a singleton list), call it c=R(s), and the other that repeatedly merges adjacent chunks when they’re out of order and gives you the best chunking, b=C(c)
Then you have C(a) \ge a fairly straightforwardly (hopefully?), and also C(a+b) = C(C(a) + b) = C(a+C(b)) = C(C(a)+C(b)) directly from merge order independence.
Also, I think that means you’re always comparing chunks (List Tx) by feerate, and chunkings (List (List Tx)) by diagram.
I was thinking of C as an operation on a list of (generalized, not necessarily monotonically decreasing feerate) chunks - whether those are obtained by starting with the singletons from a linearization, or something else.
We want to prove that C(\epsilon_n + \delta_n) \geq \gamma_n I think. I suspect it’s possible to adapt your derivation above to work by placing C() invocations carefully, and using the rules around it.
EDIT: this theorem is insufficient, as it doesn’t allow for cases where the moved good transactions get chunked together with bad transactions; a scenario that is possible in the prefix-intersection merging algorithm.
Given the following:
Under those conditions, moving the good transactions to the front of the linearization (leaving the internal order of good transactions and that of bad transactions unchanged) results in a better or equivalent linearization (by becoming the new first chunk, of feerate f).
Observe that, among the set of linearizations for the same transactions which leave the internal orderings unchanged, none can give rise to a chunk feerate exceeding f. If it did, there must be some topologically valid subset v of transactions, consisting of a union of a prefix of the good transactions and a prefix of the bad transactions, whose combined feerate exceeds f. No prefix of the bad transactions can exceed feerate f, thus there must be a prefix of the good transactions that does. This is in contradiction with the given fact that all the good transactions merge into a single chunk of feerate f.
Further observe that all good transactions merging into a single chunk of feerate f implies that any suffix of good transactions has feerate \geq f.
To prove that moving all good transactions to the front of the linearization always results in a better or equivalent linearization as the original, we will show that the following algorithm never worsens the diagram, and terminates when all the good transactions are in front:
To show that this never worsens the diagram, it suffices to see that reordering transactions within a chunk at worst leaves the chunk unchanged, and at best splits it, which improves the diagram.
Further, this algorithm makes progress as long as c_t does not start with all its good transactions. As long as that is the case, a nonzero amount of progress towards having all the good transactions at the start of the linearization is made. Thus, after a finite number of such steps, that end state must be reached.
It remains to be shown that c_t cannot start with all its good transactions unless the end state is reached. Assume it does start with all its good transactions. The set c_t \cap T is a suffix of the good transactions, and thus has feerate \geq f. Since c_t starts with c_t \cap T, the chunk c_t itself must have feerate \geq f. However, every chunk must have feerate \leq f. The combination of those two means c_t has exactly feerate f. There can only be one such chunk (as all c_i have distinct feerates), and it must be the first one (because no higher feerate is possible), so t=0. In this case, we are in the end state, because the first chunk is the only one with good transactions, and all good transactions are at its front.
I don’t like that assumption; you can only check it after you’ve done all the work, rather than beforehand, and it conceivably could turn out to be false. I think a better assumption would be “The first chunk of L has a feerate f_0 which does not exceed f”
I think by “topologically valid” you’re meaning that no parents follow their child, and that all parents are included; ie if you have c spends p spends gp, then [gp, p, c] and [gp, p] are topologically valid, but [p,c] is not. This lets you say that if b is topologically valid, then for any a,x, if a + b is topologically valid, then b + a is also topologically valid. You also have a + b being t.v implies a is t.v, and that gives you b_1 + b_2 + .. + b_n being t.v and a_0 + b_1 + .. + b_n + a_n being t.v gives b_1 + .. + b_n + a_0 + .. + a_n being t.v.
For the intermediate steps, you’re not moving txs all the way to the front, though, so I think you want something slightly cleverer still; perhaps a + b + c and a + c being t.v gives a + c + b being t.v is enough.
I think you could rewrite this slightly:
Note that your good txs will never get split up once you’ve moved them, so c_0 will have the same composition and feerate it had originally until t=0 and c_0 \cap T = T, and merging some subset of the good txs into c_{t-1} will mean all of them are merged.
Also, I think your theorem needs a tweak: if you have equal size txs with feerates a=0,b=6,c=9,d=0,e=5, and start with L=[a,b,c,d,e] and T=[a,e], then your original chunks were [a,b,c], [d,e] with both those chunks and T having a feerate of 5. But your new linearisation of [a,e,b,c,d] chunks to [a,e,b,c] [d] with feerates 6.25 and 0. Which is fine, it’s just that T doesn’t actually become the first chunk, since we end up finding a chunk with feerate greater than f instead.
It can be checked beforehand: it’s just the feerate of the first chunk of L \setminus T is \leq f.
Hmm, indeed, that would be a better starting point, as it exactly matches the conditions in the actual prefix-intersection merging algorithm. And it’s not equivalent to mine (as your example at the end of your post shows; in that example the highest chunk feerate of bad transactions is 7.5 which exceeds f=5). I’ll think about generalizing it.
Indeed, something like this needs to be included in the proof. Also further, it’s currently unclear why it’s even allowed to move the c_t \cap T transactions to the front of c_t.
I don’t think you need an argument about what happens to c_t after rechunking. It’s sufficient that progress was made by moving a nonzero number of transactions towards the front. If you can keep doing that, all of them will end up at the front of L. And we prove progress will keep being made until they are all at the front of L, so that is indeed the end state.
Note that I started off by merging equal-feerate chunks, so there can be at most one chunk for any given feerate.
Right, this example does capture a situation we want the theorem to cover, but it currently doesn’t.
Sadly, the proof breaks entirely when chunks with feerate > f are permitted. It is possible, by following the “move good transactions to front of last chunk that has any” algorithm, to end up in a situation that’s better than the desired end state (all good transactions up front). The theorem is still likely true, but the proof technique of individual move steps to achieve it does not work, unless it can somehow be amended to never improve beyond the goal.
New attempt, with a fully “geometric” approach to show the new diagram is above the old one, but largely using insights about sets from @ajtowns’s proof sketch above.
Given:
Then:
Let’s call this the gathering theorem (it matches what the VGATHER* AVX2 x86 CPU instructions do to bitsets).
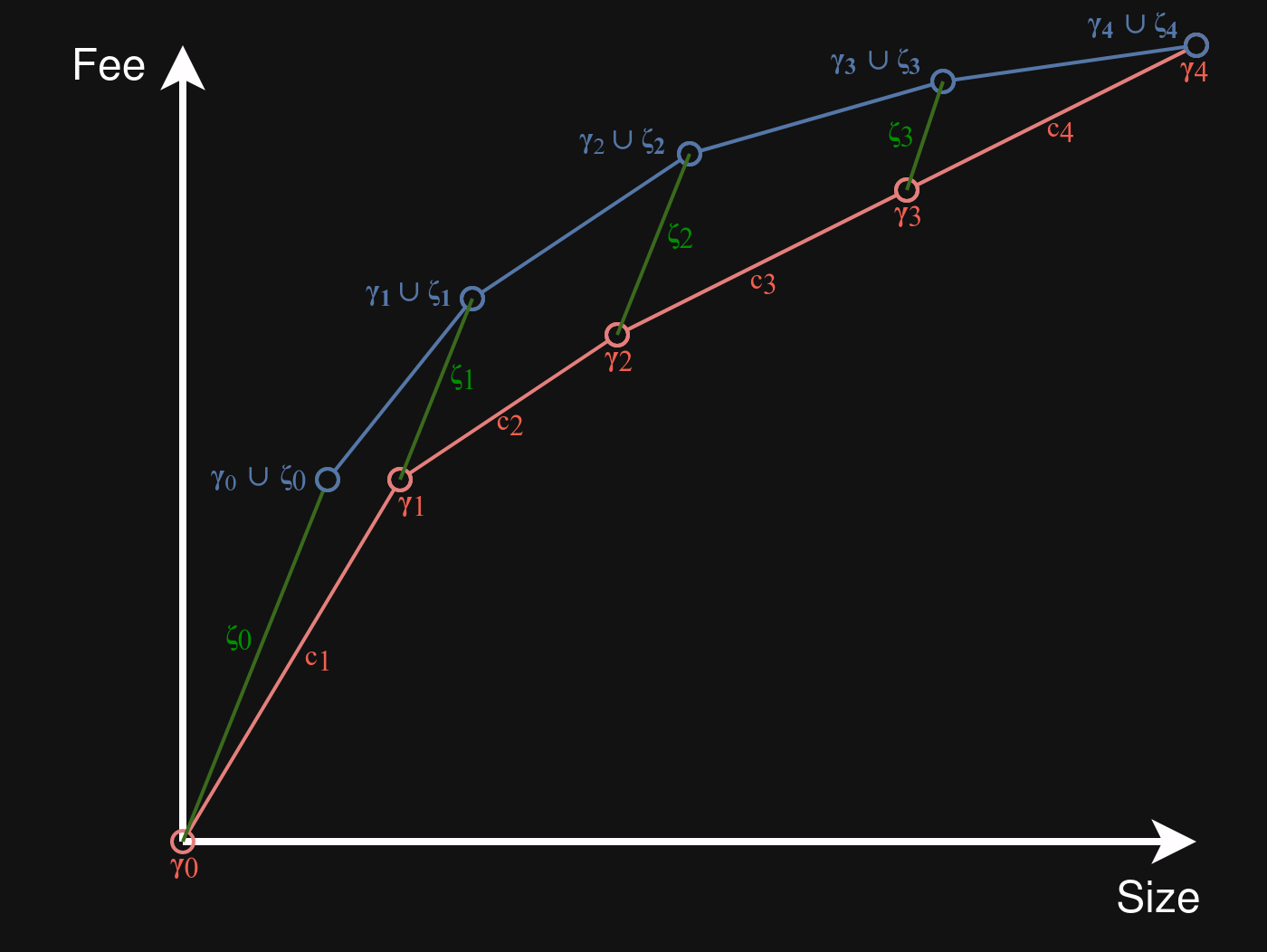
In the drawing below, the blue diagram formed using the \gamma_i+\zeta_i points (plus initial green \zeta_0 segment) is an underestimate for N, the diagram of L_G+L_B. The red diagram shows D, the diagram for L. Intuitively, the blue diagram lies above the red diagram because the slope of all the green lines is never less than that of any red line:
In what follows, we will show that every point on N lies on or above a line making up D. If that holds, it follows that N in its entirety lies on or above D:
Thus, all points on an underestimate of the diagram of L_G + L_B lie on or above the diagram of L, and we conclude that L_G + L_B is a better or equal linearization than L.
It is easy to relax the requirement that L_G forms a single chunk. We can instead require that only the lowest chunk feerate of L_G is \geq f. This would add additional points to N corresponding to the chunks of L_G, but they would all lie above the existing first line segment of N, which cannot break the property that N lies on or above D.
Merging individually post-processed linearizations (thus, ones with connected chunks) may result in a linearization whose chunks are disconnected. This means post-processing the merged result can still be useful.
For example:
graph BT
T0["B: 5"];
T1["C: 10"] --> T4;
T2["D: 2"] --> T4;
T3["E: 2"] --> T0;
T3 --> T4;
T4["A: 1"];
I think the intuition for this is that you’re constructing a (possibly non-optimal) feerate diagram for L_G+L_B by taking the subsets L_G + \sum_{i=1}^j d_i and showing this is a better diagram than that of L. Because you can’t say anything about d_i (the bad parts of each chunk), you’re instead taking the first j chunks as a whole, which have a feerate of f or lower, and then the suffix of L_G that was missed, which has a feerate of f or high, which kinks the diagram up. Kinking the diagram up means this subset has a better diagram than the chunks up to and including c_j.
FWIW, I think this was the argument I was trying to make in my earlier comment but couldn’t quite get a hold of.
I think the general point is just: L^* \ge L if (and only if?) for each \gamma_i (prefixes matching the optimal chunking of L) there exists a set of txs \zeta_i where \gamma_i \cup \zeta_i is a prefix of L^* and R(\zeta_i) \ge R(\gamma_i).
Ah! Actually, isn’t a better “diagram” to consider the ray from the origin to these P(\gamma_i) points in general, ie, for x=0...c_1 plot the y value as R(\gamma_1), for x=c_1..c_2 plot R(\gamma_2) etc. Then (I think) you still compare two diagrams by seeing if all the points on one are below all the points on the other; but have the result that for an optimal chunking, the line is monotonic decreasing, rather than concave.
Also, with that approach, to figure out the diagram for the optimal chunking, you just do the diagram for every tx chunked individually, it’s just f_{opt}(x) = \max(f(x^\prime), x^\prime \ge x).
Exactly. I’ve added a drawing to illustrate this, I think.
Do you perhaps mean plotting F(\gamma_i) (fee) instead of R(\gamma_i) (feerate)?
If so, that’s always monotonically increasing (just because fees are never negative).
FWIW, I think you don’t need case \gamma_0 + \zeta_0 in your proof, just the ones after each chunk suffice.
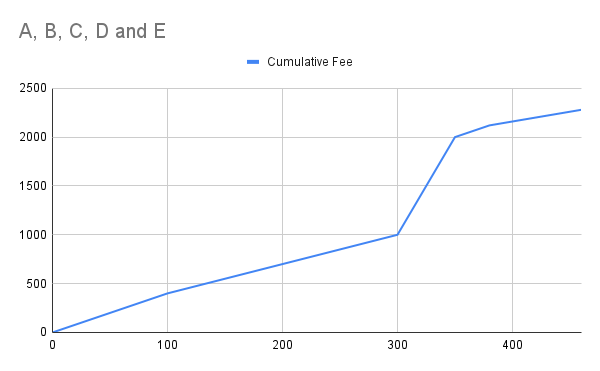
No, I meant fee rate – plotting fee gives you the current diagram, eg:
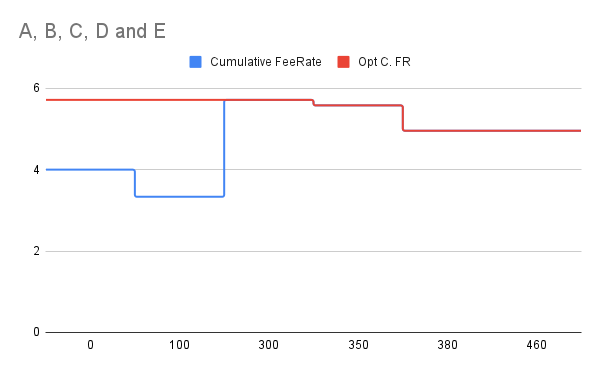
Plotting fee rate looks like:
Spreadsheet to play around: cfeerate - Google Sheets
I think that’s a question of formality. It’s of course obvious that if all points after each chunk lie above the old diagram, then the line from the origin to the first point does too. Yet, we actually do require the property that that line in its entirety lies above the old diagram too. Depending on how “obvious” something needs to be before you choose not to mention it, it could be considered necessary or not.
I don’t think this works. It is very much possible to construct a (fee) graph N that lies above graph D everywhere, but whose derivatives (feerates) aren’t.
EDIT: I see, you’re talking about average feerate for the entire set up to that point, not the feerate of the chunk/section itself. Hmm. Isn’t that just another way of saying the fee diagram is higher?
No, I mean that you can just choose the origin for your first point and go straight to \gamma_1 \cup \zeta_1 when constructing N, and run the same logic.
Yes, precisely – it is another way of saying the same thing, I think it’s just easier to reason about (horizontal line segments that decrease when you’ve found the optimal solution).
Translating the N is better than L proof becomes: look at the feerate at \gamma_i; now consider the feerate for \gamma_i + \zeta_i – it’s higher, because \zeta_i \ge f and the size of that set is greater, and an optimal chunking will extend that feerate leftwards, so N chunks better up to i, for each i, done. You don’t have to deal with line intersections.
Right, that works, we could just drop \gamma_0 \cup \zeta_0 from N. I don’t think it actually simplifies the proof though, because the reasoning for the first segment (now from (0,0) to P(\gamma_1 \cup \zeta_1)), would still be distinct from that for the other segments.
Consider the following:
Yeah, agreed; was more just thinking from the general case where \zeta_i might not have the same nice pattern.
Hmm, you’re right, my simplification to a flat graph doesn’t seem to do anything useful. ![]()
[EDIT: added the ![]() emoji as a possible post reaction]
emoji as a possible post reaction]
Interesting, it appears that prefix-intersection merging is not associative.
That is, given 3 linearizations A, B, C of a given cluster it is possible that not all three of these are equally good:
This holds even when the inputs, intermediary results, or outputs (or any combination thereof) are post-processed.
Prefix-intersection merging can be simplified to the following:
So we only need to find the best prefix of the intersection of the highest-feerate prefix with the other linearization, and not the other direction.
This does not break the “as good as both inputs” proof, and from fuzzing it appears it that this doesn’t worsen the result even (it could be that this results in worse results while still being at least as good as both inputs, but that seems not to be the case).
I don’t have a proof (yet) that the algorithms are equivalent, but given that it’s certainly correct still, it’s probably fine to just use this simpler version?
If you have L1=[5,3,1,8,0] (chunk feerates: 5, 4, 0) and L2=[0,8,1,3,5] (chunk feerates: 4, 3) then bestPi chooses C=L2 \cap [5] to start with, ending up as [5,8,3,1,0]. Whereas calculating and comparing C_1 and C_2 would produce [8,5,3,1,0].
But post-processing probably fixes that for most simple examples at least?
(Even if post-processing didn’t fix it; I think so long as merging produces something at least as good as both, that’s fine; quicker/cheaper is more important)
I think you can make post-processing fail to help for this example just by adding a small, low-fee parent transaction P that is a parent to both the 8-fee and 5-fee txs.
I think if you have five transactions, A,B,C,D,E, of 10kvB each at 50,30,10,80,0 sat/vb, and one transaction, P, at 100vB and 0 sat/vb that each of A,D spends an output of, with the same arrangement as above, then post-processing doesn’t fix it either?
Post-processing (work marked with *):