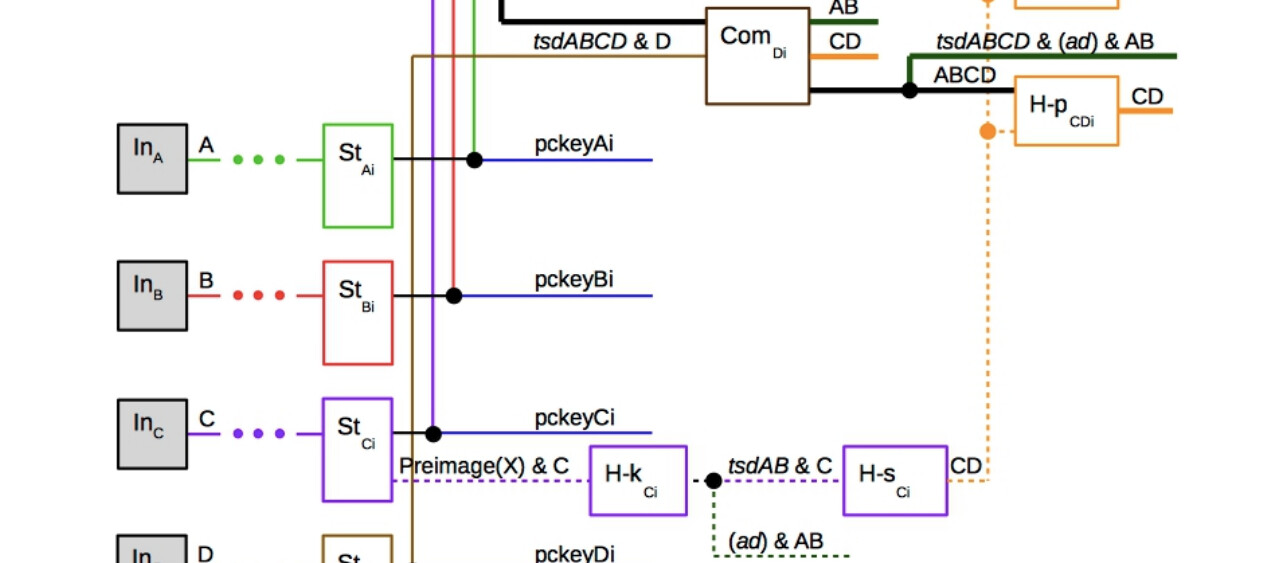
Contract-level Relative Timelock (CLRT) UTXO for Eltoo
Eltoo constructs such as ln-symmetry suffer from an issue where every time an update transaction is confirmed on the blockchain, the relative timelock to settle the contract is reset. This causes further funds lockup, and further extends HTLC expiry in the LN use-case, potentially reducing network utility.
How can we have a “contract” level relative timelock? Embedding state inside the continuously refreshed utxos seems intractable due to Bitcoin’s requirement for monotonic validity of transactions. An adversary can simply “under-report” the number of “elapsed” blocks during the contract’s lifetime. The proposed solution here is to dedicate a specific utxo that doesn’t move until the the challenge period is over, and only allowing the contract state output and relative timelock output to be spent concurrently.
LN-symmetry and extension?
To recap, ln-symmetry has this series of transactions that must appear to settle the contract:
funding->update->settle
For this extension we change it to include a slightly different update transaction we will call “kickoff”:
funding->kickoff->update->settle
Kickoff transactions have an additional CLRT output that
commits to a relative delay (ln-symmetry’s shared_delay) for the eltoo challenge period
before the settlement transaction can be confirmed.
The output is dust-level and commits to being spent concurrently with an eltoo state output. To do this, you need a recursive proof that links back to an update transcation’s state output. In other words, the recursive proof needs to demonstrate that another input has an ancestry that includes the kickoff transaction itself.
Update transactions pre-commit to both the state output(s) and the CLRT output to enforce that if the state output is spent, so is the CLRT output.
This makes mutual spending of a state output and CLRT a requirement for settlement.
How could the CLRT ancestry proof work?
Make the problem simpler: Assume TXID stability
If we accept the case where we are just doing “onchain” eltoo with normal SIGHASH_DEFAULT,
this becomes a lot simpler due to txid stability of the eltoo chain. The CLRT output becomes
a connector output that is “re-attached” via consensus signatures of channel participants, and the script being a simple CSV of the shared_delay.
Obviously, requiring O(n) state on-chain is sub-optimal, but I think it’s important to have a correct construction for demonstration purposes.
Another usage, at least on paper: Used for sequencing transactions in John Law’s constructions of channels
Without TXID stability
Once we venture into “real” eltoo where we are re-attaching prevouts, transaction id stability goes out the window and we cannot rely on regular signatures to authorize the connector output.
High-level handwave solution:
- CLRT introspects “current” input’s prevout. This will be matched in ancestry proof next.
- Proof contains first submitted update transaction with matching kickoff prevout, computes its txid, checks that second confirmed update transaction in proof spends that utxo, etc, until proof connects with the settlement transaction itself in the state output being spent. The proof checker MUST enforce the right outputs are being spent at each step: the state output of the eltoo contract, rather than say an anchor output.
Problems:
- Requires some sort of consensus change to support proof construction, leaving this as exercise to reader.
- Kickoff transaction and additional utxo costs extra vbytes and adds lots of complexity.
- Proofs are vbytes-expensive and allow counterparty to penalize honest partner by doing additional updates.
- Crucially, the counter-party can make it consensus-invalid to actually spend the CLRT by inflating the proof beyond consensus limits. Either need a mechanism for fixed number of updates and constant sized updates, or ZK magic to compress the proof to constant size?
If we get OP_ZKP maybe it becomes practical with O(1) enforcement of transaction ancestry?
Are there simpler solutions to this problem I’m missing?
Appendix: Chia Version
h/t @ajtowns
With Chia’s coinid, I think this gets pretty simple, but is still linear in update history:
reminder that CoinID = SHA256(parent_coin_id || puzzle_hash || amount)
Assuming the signature being used is functionally equivalent to SIGHASH_ALL and there is some sort of simplistic P2A like output for fees, that means there will be two types of outputs in each update: a contract output, and a static P2A-like puzzle we can filter for.
For witness data you are given a series of 32WU puzzle_hashes, none of which can be the P2A-equivalent. You take CLRT’s parent coin id, and repeatedly hash it with the static amount and series of puzzle hashes. At the end, the coinids should match expected.
At 32WU per update, a standard relayable transaction could include a proof up to 12,500 levels, minus overhead.