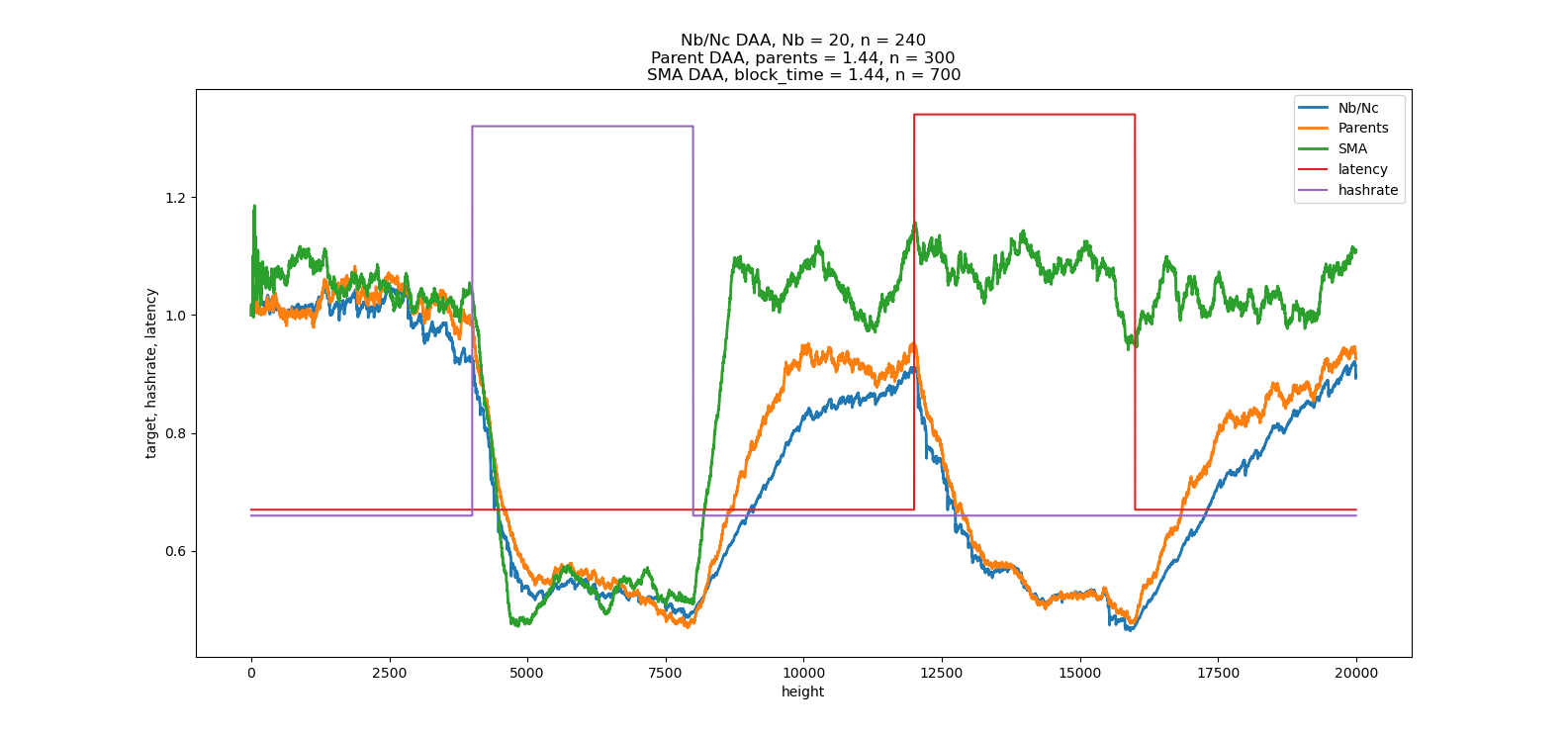
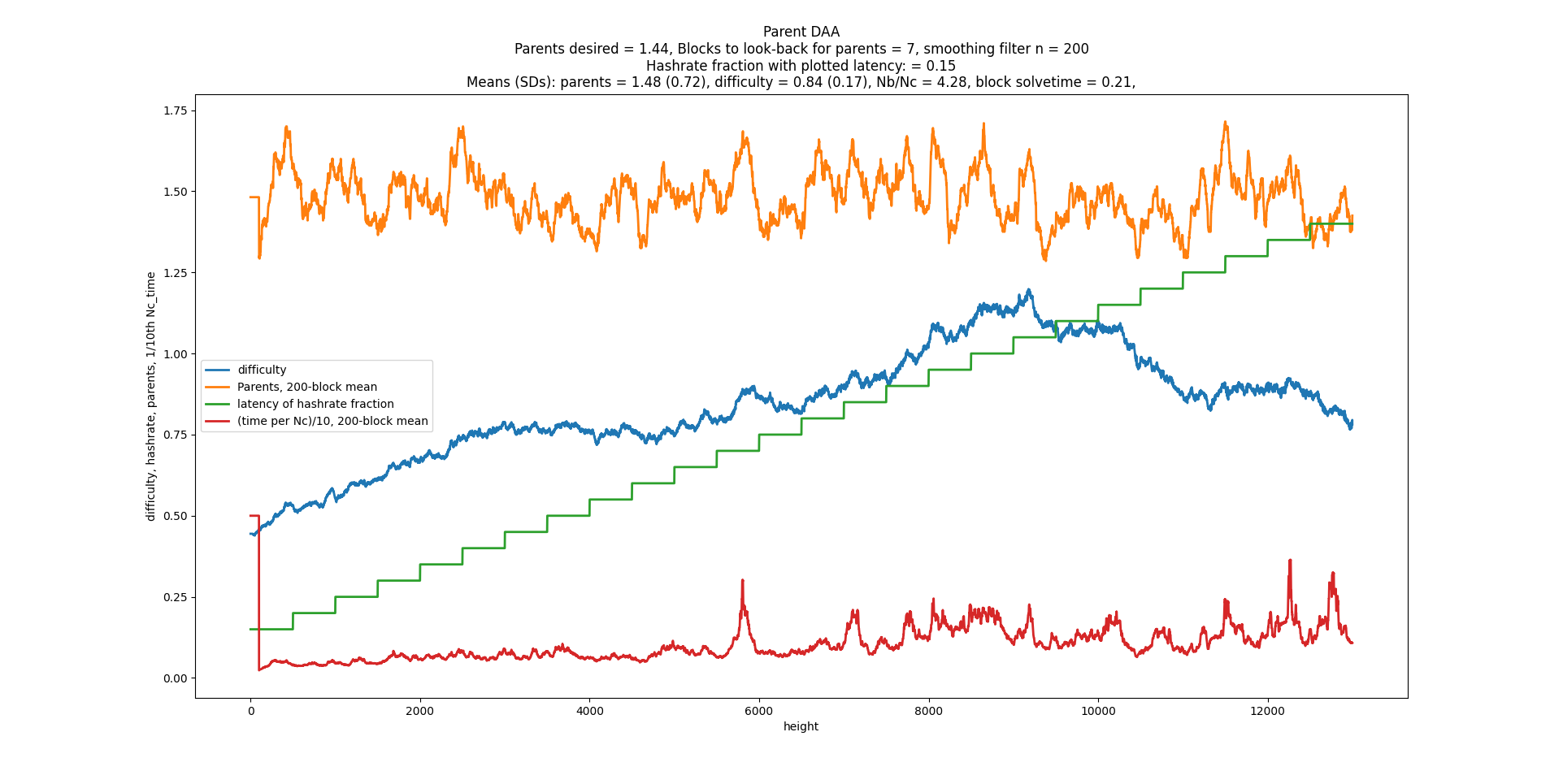
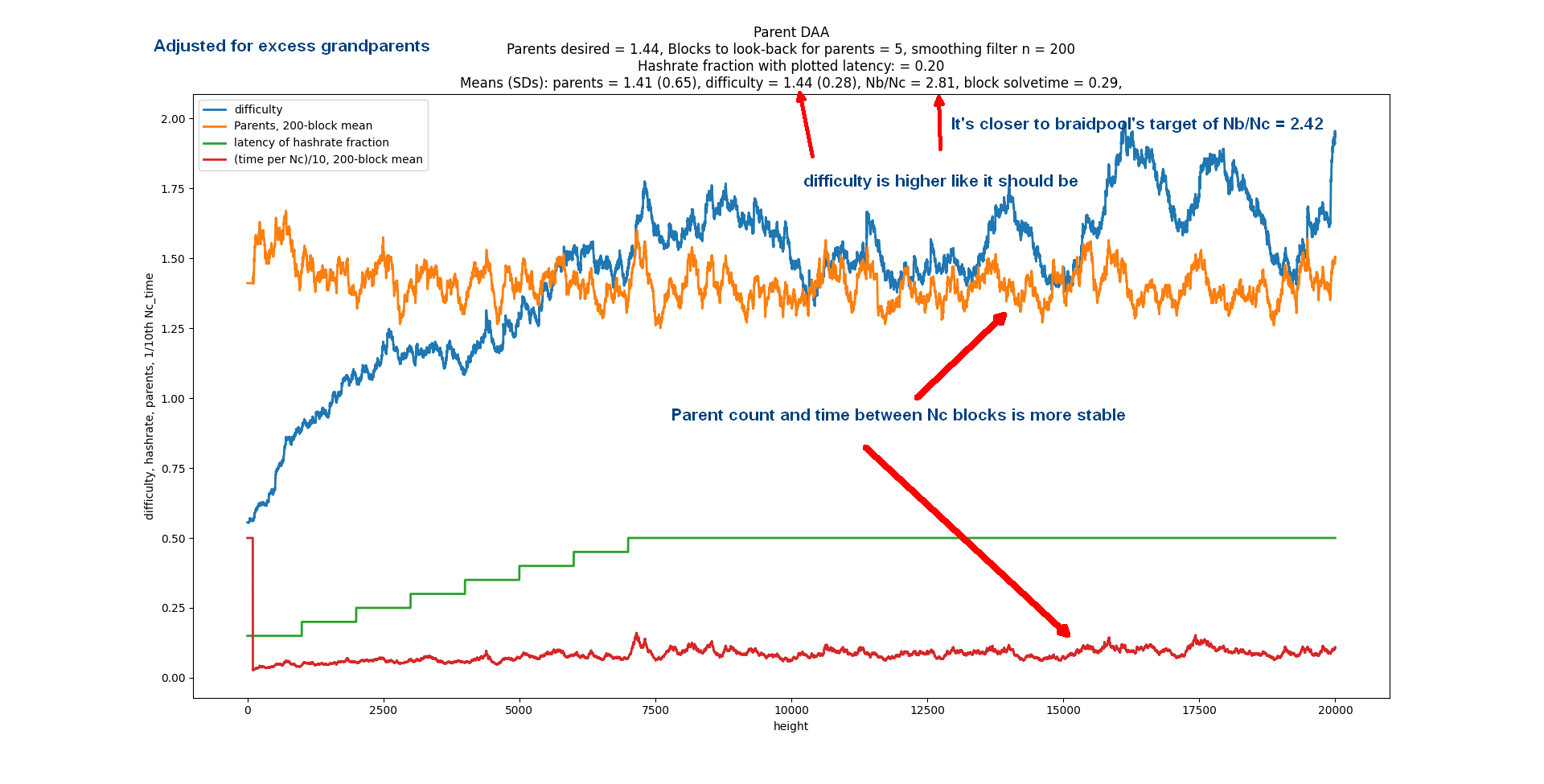
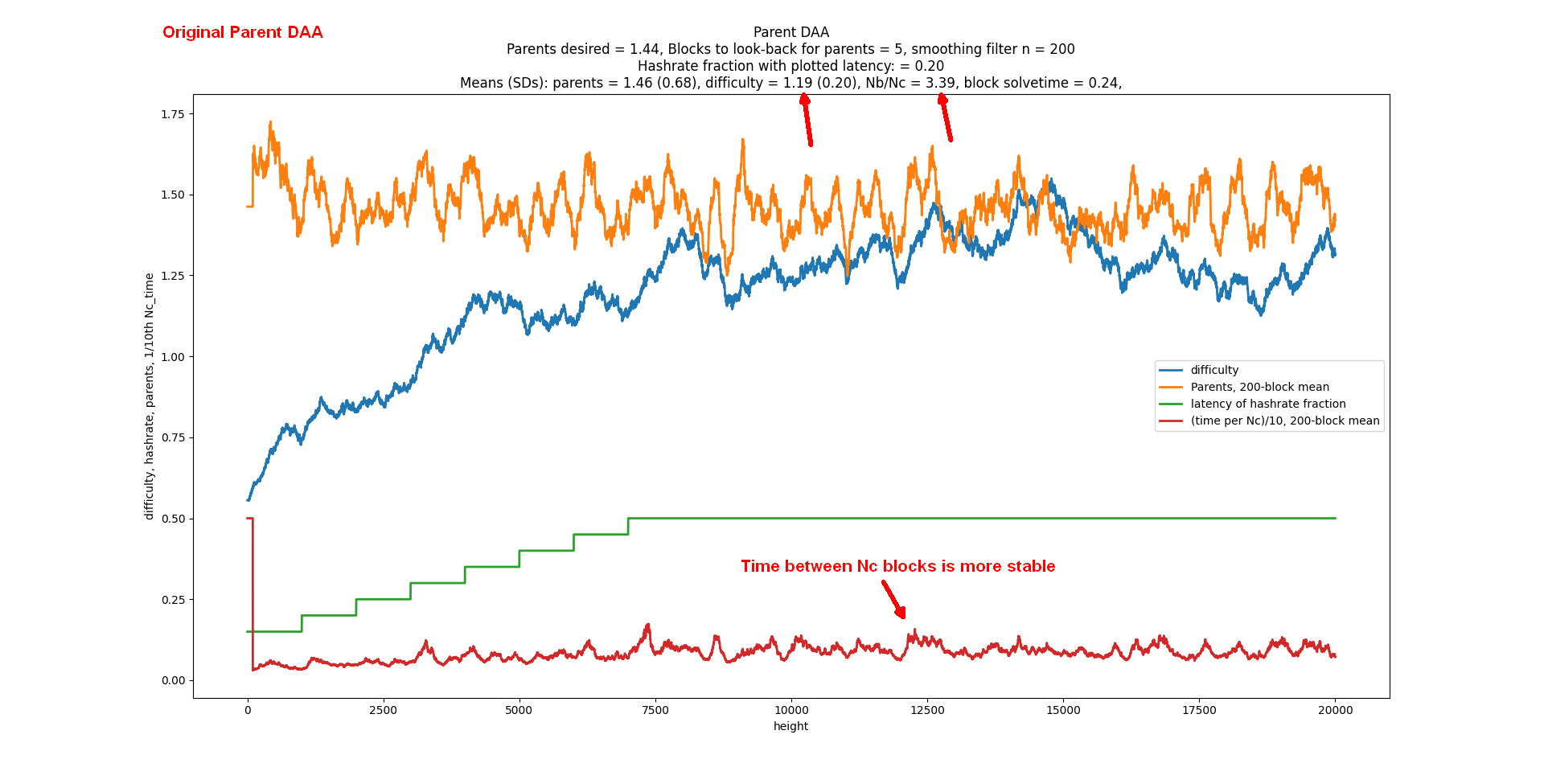
I was helping Bob McElrath on his difficulty algorithm for Braidpool and found a remarkable difficulty algorithm that doesn’t use timestamps, hashrate, or latency. Its goal is to be the fastest-possible consensus. Hashrate and latency independently create a wider DAG when they go up. But when you’re doing making it as fast as possible, hashrate * latency precisely cancels time units. You can simply set difficulty to target the DAG width.
Bob’s simple way of getting consensus is when the DAG width = 1 so that all nodes can agree what state the system was in. Width = 1 occurs when a block is the only child of the previous generation of blocks and the only parent of the next generation. This occurs when he’s the only block mined in 1 latency period after he sends it, and not block is mined in 1 latency period after everyone has received it.
But how do we measure DAG width? You just count your parents and target a fixed number of parents. This is an extremely simple idea compared to other DAG schemes that have to examine and think about a large tree of blocks.
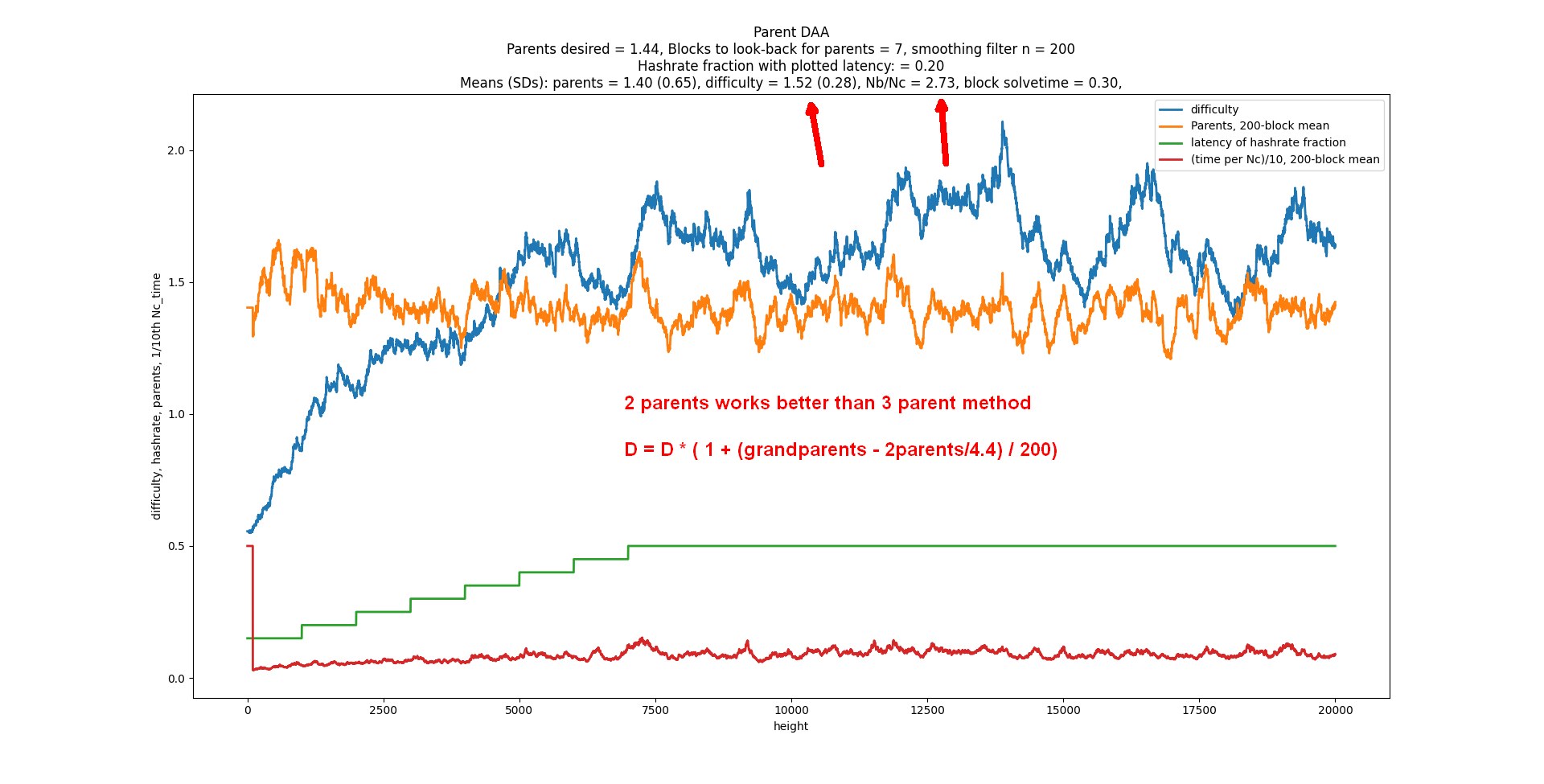
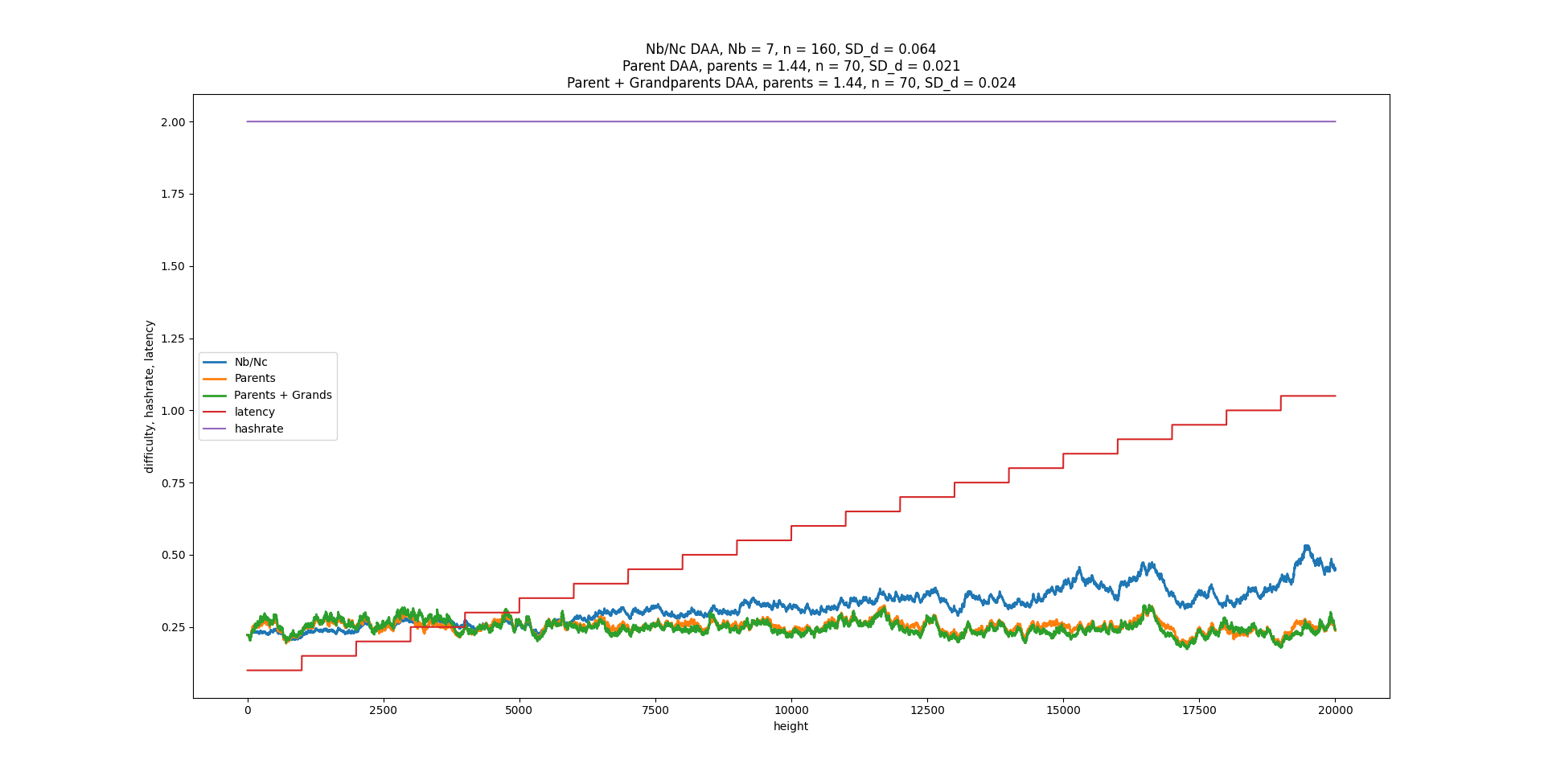
What the best number of parents? It turns out 2 gives the fastest consensus (i.e. the fastest time between 2 blocks at DAG width=1). When you target 2.000, the StdDev of number of parents is 1.000. But wait, there’s more. Consensus is achieved in exactly 2.71828x the latency, where latency is defined as the delay for all nodes in receiving a block. It’s 2x faster if you define latency as the median. Another interesting thing is that the ratio of total blocks to the consensus blocks is also 2.7182. Maybe someone could do the math to explain why.
Here’s the DAA:
D = D_parents * (1 + parents/100 - 2/100)
if parents average > 2 in past 100 blocks, D goes up, and vice versa.
Here’s the command line output of my simulator below.
User chose to use 'a' as the exact latency between every peer.
===== User selected parent-count DAA. =====
x = x_parents_hmean * ( 1 + desired_parents/n - num_parents_measured
median a L parents desired n blocks
1.00 1.0 2 500 50000
Mean StdDev
x: 0.995 0.030 (Try to get smallest SD/mean for a given Nb*n.)
solvetime: 1.006 1.008
Nb/Nc: 2.694 0.059
num_parents: 2.004 1.007
Nc blocks: 18561
Time/Nc/a: 2.712 (The speed of consensus as a multiple of latency.)
DAG simulator by counting parents
Equivalence to Avalanche Speed and Efficiency: Basically, fees in both systems dictate how much “waste” you can spend on making it distributed and secure. Avalanche is so proud the number of messages/node doesn’t go up any as the number of nodes increases, but the network-wide waste in sending each other messages linearly goes up. Peers are basically “mining each other” with messages to get consensus. I don’t say mining here lightly. It’s very much the same level of waste for the same reasons with the same inefficiency. Network bandwidth is precious and expensive. PoW does local hashing to remove the need for network messaging. Fees determine how much waste either system has and fees => waste is the source of security and decentralization.
- Avalanche <=> PoW
- messages = hashes
- more nodes = more hashing
- stake = CAPEX in mining equipment
- fast = this DAG