Hi all,
I have developed a new UTXO database, custom designed for maximizing throughput on Bitcoin consensus validation. I call it Hornet UTXO(1) because the queries are constant-time.
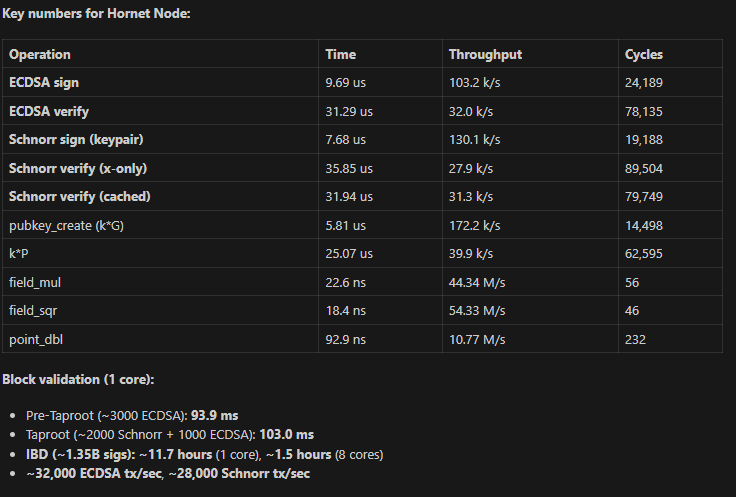
This is a new component of Hornet Node, my experimental Bitcoin client focused on declarative consensus specification and high performance. I intend to do a full write-up but I’m posting preliminary results here to get feedback from the community first.
The database has been developed from scratch in modern C++. It has been designed for maximum parallelism so it’s highly concurrent and lock-free.
On my 32-core dev workstation, these are like-for-like results for re-validating the whole mainnet chain without script or signature validation:
- Bitcoin Core: 167 minutes
bitcoind -datadir="/nvme1/bitcoin/" -reindex-chainstate -dbcache=24000 -connect=0 -assumevalid=0000000000000000000019426fb9e93a5cfa7695f271d928beeddf39a1ef3f3f - Hornet UTXO(1): 15 minutes
In this benchmark, both processes perform all structural and contextual validation, build the UTXO database, and validate all tx inputs correspond to unspent outputs.
The core operations of Append, Query, and Fetch can all be executed concurrently and lock-free. Blocks can be submitted for validation out of order as they arrive, and will be processed concurrently, with data dependencies automatically resolved.
Entries in the database index are height-tagged so that state can be rewound to a fork point for reorgs without storing additional undo state. This also allows queries to be issued against a specific past chain state.
The serial dependency on a previous block’s transactions is minimized by:
- Allowing non-dependent work to progress concurrently;
- Performing pre-emptive Append operations (that can be unwound in a failure case);
- Allowing partial queries and fetches against the existing data.
Disk access is optimized via asynchronous, high queue-depth requests. Memory is optimized via compact, cache-friendly data structures and fixed-size allocations.
The implementation is succinct at only 3,000 lines of C++23 with no external dependencies. There are no hash maps involved as sorted arrays and LSM trees are preferred.
For those who missed it, you can read about the broader Hornet Node project here:
T. Sharp (2025). Hornet Node: A Declarative, Executable Specification of Bitcoin Consensus. HTML // PDF
(Thanks to the people who got in touch to encourage me with this project. I really appreciate it.)
I would be interested to hear feedback, questions, or about related work that I’m probably unaware of. I can then make sure it all gets addressed in the formal write-up.
This is currently an unfunded personal project developed in spare time. If you would like to support continued development, you can donate here: 33Y6TCLKvgjgk69CEAmDPijgXeTaXp8hYd.
If you’re in industry and you’re interested in faster IBD validation times to bring nodes online, please reach out.
Best wishes, T♯