Problem
Current wallets are not optimized for liquidity providers like Lightning nodes that fund requests for liquidity via liquidity ads.
Liquidity provider wallets have a usage pattern with these characteristics:
- frequently spend utxos of known amounts to liquidity transactions
- infrequently refill the wallet when the balance gets low
- liquidity transactions may not confirm before the next spend (simultaneous spends)
- liquidity transactions may not confirm at all due to inputs from other wallets (unsafe change)
Ideally every liquidity transaction could be funded with a single input and without a change output. This has the lowest weight/fees and does not tie up funds in a change output that may take a long time to become spendable or that may not confirm at all (see liquidity griefing).
Given these constraints and goals, how should a wallet manage the utxo set for liquidity providers?
We have a proposed solution, but would appreciate any thoughts on how best to optimize utxo management to decrease aggregate on-chain fees and increase the ability to fund multiple simultaneous funding transactions.
Proposed Solution
To fund a new liquidity transaction, perform the following steps:
- Import a user defined set of target utxos we want to have available to fund liquidity transactions.
To provide liquidity of 0.001 BTC with a single input and no change you need a utxo of that amount plus the cost of the transaction at the current fee rate. Each target requires a bucket of utxos suitable for different fee rates. The number of utxos in a bucket depends on how many simultaneous transactions you need to support and the range of likely fee rates. Coin selection algorithms will select a utxo that overpays fees when it costs less than adding an additional input and change output.
- Proactively refill buckets in some situations.
When fee rates are low, or a bucket is extremely depleted, we should proactively create change outputs to refill buckets. Initially I propose adding the largest utxo that is not in a bucket as an additional input to the transaction. This input will be split in step 4 to refill depleted buckets. We should not deplete full buckets to refill depleted ones. At that point it makes more sense to refill the wallet with new value from cold storage.
- Opportunistically refill buckets if coin selection adds a change output.
When coin selection can not find a solution with a single input and no change, it will search for a solution with a change output of at least some minimum amount of value. That change output should opportunistically refill one (or more) of our target buckets. This can be done in different ways. Initially I propose setting the minimum change output size to an amount that refills the most depleted target bucket. This may add utxos from existing buckets.
- Split the change output, if any, to refill buckets.
When coin selection generates a transaction with a non-zero change amount, that amount should be split into outputs that refill our target buckets. I initially chose to iteratively select the most depleted bucket until the remaining change amount was less than the next depleted bucket or when all buckets are at capacity. The remaining change amount then goes into the last change output.
Testing
I ran some test with a modified fork of coin_selection_simulation and with the changes to Bitcoin core in draft PR #29422.
Results
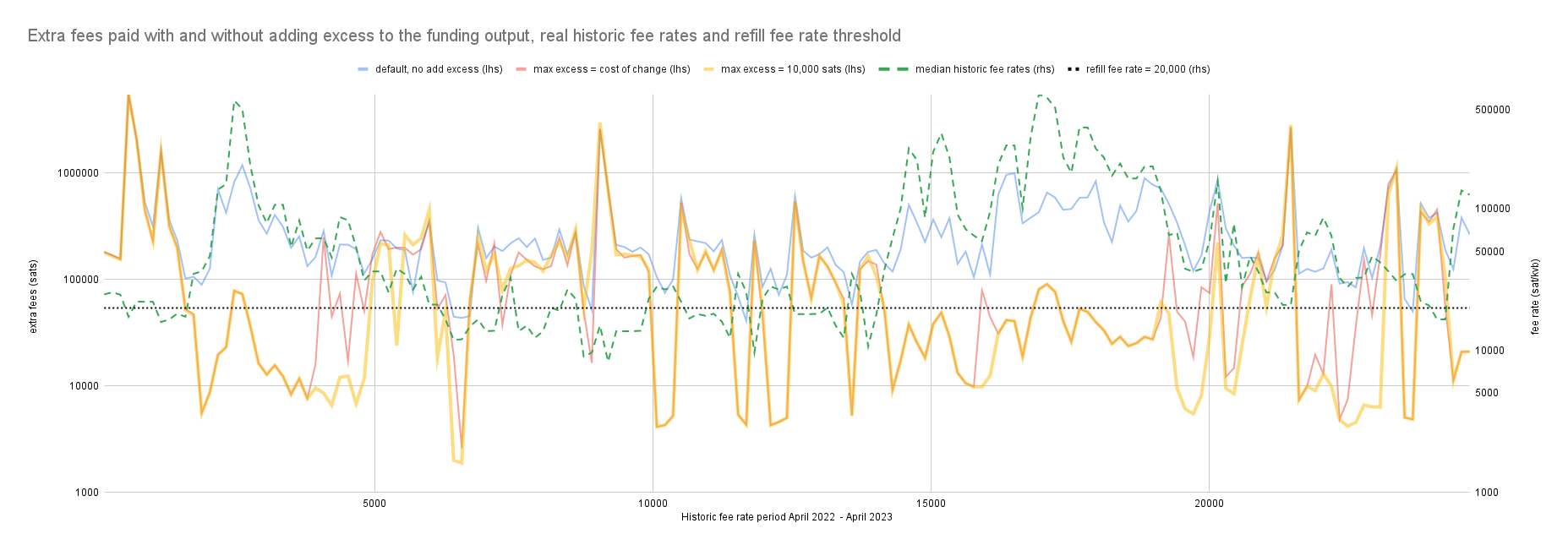
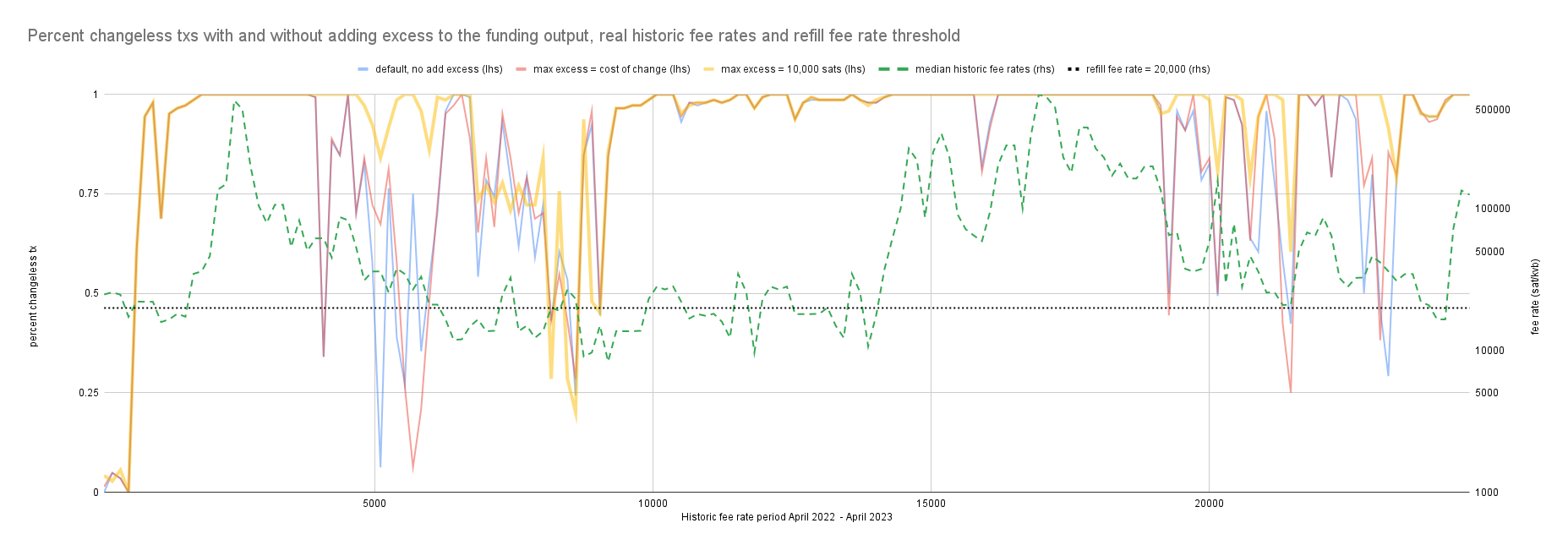
My initial results using the above changes appear to yield a 15% reduction in on-chain fees compared to default coin selection. I think further improvements and refinements can be made and I would appreciate any suggestions.
Questions
- Does the concept of performing pre/post processing on the parameters of coin selection make sense or is there some way to optimize coin selection itself for this scenario?
- Would it make sense to only use branch-and-bound and CoinGrinder as coin selection algorithms for this problem to reduce fees?
- Any ideas for a better algorithm for adding inputs and splitting change to converge on our target utxo set with the least on-chain fees?
- Are there other use cases that could use this functionality? coin join users perhaps?