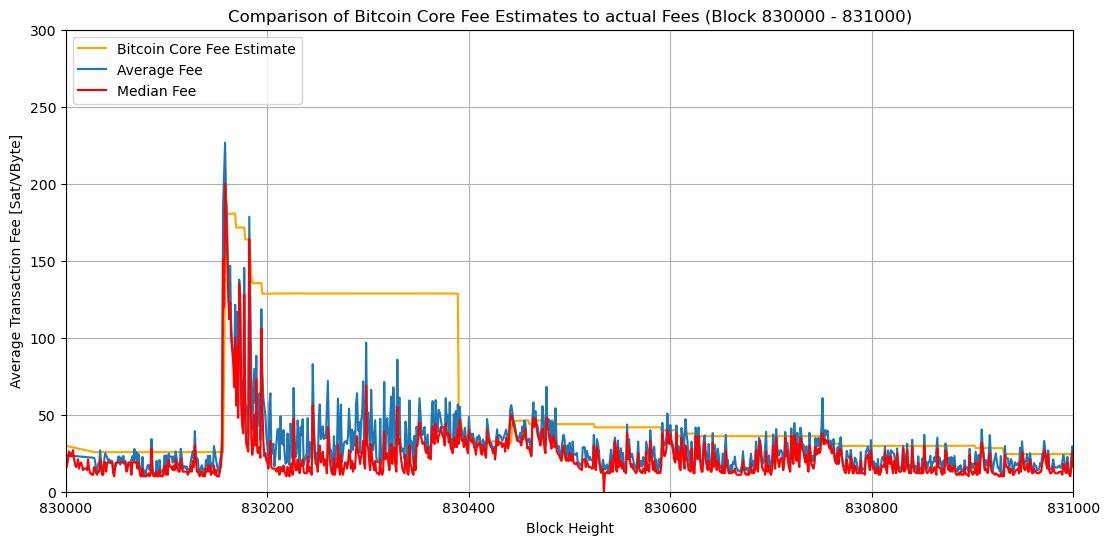
Mempool-Based Fee Estimation in Bitcoin Core
A Node can get a fee estimate by generating a block template from mempool transactions, using the fee rate of the transaction/package at the 50th percentile[0] of the generated block weight as the fee rate estimate k for the next block.
Creating a new transaction/package with the same fee rate as k will align it with transactions/packages in the block template and will likely be included in the next block when propagated in the network.
Relevance of mempool-based fee estimation.
-
It is assumed that most miners are generating block templates they intend to mine next from their node’s mempool[1]. Hence placing a bid using mempool-based fee estimation puts the transaction/package in the same rank as the transactions/package in the block template miners are processing and will most likely be included in the block. As such, if your mempool is roughly in sync with miners this is the most accurate method of ensuring your transaction gets mined in the next block.
-
It quickly reacts to changing conditions when the mempool is full due to high block confirmation time or the user’s mempool becomes shallow.
Instances where mempool-based fee estimation falls short.
-
When a node’s mempool diverges with the network miners’ mempool, assumptions will be wrong and lead to inaccurate results.
- This will happen due to the policy rules[2] of the node.
- The peers connected to a node, i.e. how well connected the node is in the network to get information on all the transactions being broadcasted in the network.
-
If miners are accepting most of the transactions they mine via other means than the P2P network, users’ mempool will not be roughly the same as miners.
-
The mempool-based fee estimate for confirmation target > 1 is unreliable due to mempool changing conditions. When the confirmation target is > 1 block in the future the mempool conditions will likely change e.g. high confirmation time, high demand for block space. Assertions made on the miner’s block template previously will not hold.
-
The node might be accepting some transactions that miners might not accept into their mempool due node’s lax policy rules[2] and this will mess with their estimate.
How do we know if a node’s mempool aligns with the network or not?
-
By adding sanity checks that will serve as indications of whether a node is roughly in sync with miners in the network or not based on previously mined blocks and the transactions that are in the node’s mempool at the time the previous block was mined. Whenever we suspect that a node’s mempool diverges from miners we prevent the node from getting a fee estimate.
-
We can do this by checking if most of the transactions in previously mined blocks were present in the node’s mempool when the target block arrived.
-
Check if the node’s mempool high mining score transactions are getting confirmed.
-
-
We can count the number of times we had expected a mempool transaction with a high mining score to confirm and it did not, if its count value reached a certain threshold we prevent considering the transaction when generating a block template, it’s most likely that miners don’t consider this transaction.
- The idea for these sanity checks was taken from this issue description Improving fee estimation accuracy · Issue #27995 · bitcoin/bitcoin · GitHub
Limitations of the sanity checks.
-
These sanity checks are based on the past blocks and past mempool; they will not accurately tell us that the node’s current mempool is likely the same as miners.
-
The checks only give some confidence that if previously our mempool was roughly in sync with miners then we can use it for fee estimate because it’s most likely the node is widely connected and maintains sane policy rules that are alike with miners, and the network miners are also picking from the broadcasted transaction in the network. That might not always be true. I can’t think of a scenario when it will not be true.
Implementation of mempool-based fee estimation with the sanity check
The challenge of mempool-based fee estimation Implementation above.
- Performing these sanity checks requires that immediately after a new block is connected we build a block template[3] we are expecting before evicting the block transactions from the node’s mempool, building a block template has roughly O(n*m) (n is the total mempool transaction and m is mapModified transactions) which might take some time and we don’t want any expensive code execution at that code path as it will slow block propagation in the network.
Post cluster mempool, we will have a total mempool ordering, enabling getting the block template in linear time. Hence getting the expected block template after a new block is connected is not expensive.
Is it worth adding this feature?
We can have an RPC with this estimation mode that users can manually use as the fee rate of their transactions/packages. Subsequently, in the future, we can automate it in the wallet if it is deemed to be reliable.
Cluster Mempool is still a work in progress, What is the way Forward?
-
CBlockPolicyEstimator[4] is the current fee estimation being used by Bitcoin Core and its dependencies which has known issues[5] of Overestimating / Underestimating fee rates and in some cases making transactions become stuck in the mempool due to inaccurate estimates. -
We can have a mempool-based fee estimator without any sanity check, available from an experimental RPC that can be used by node users with caution. and then add the sanity checks upon deployment of Cluster mempool.
-
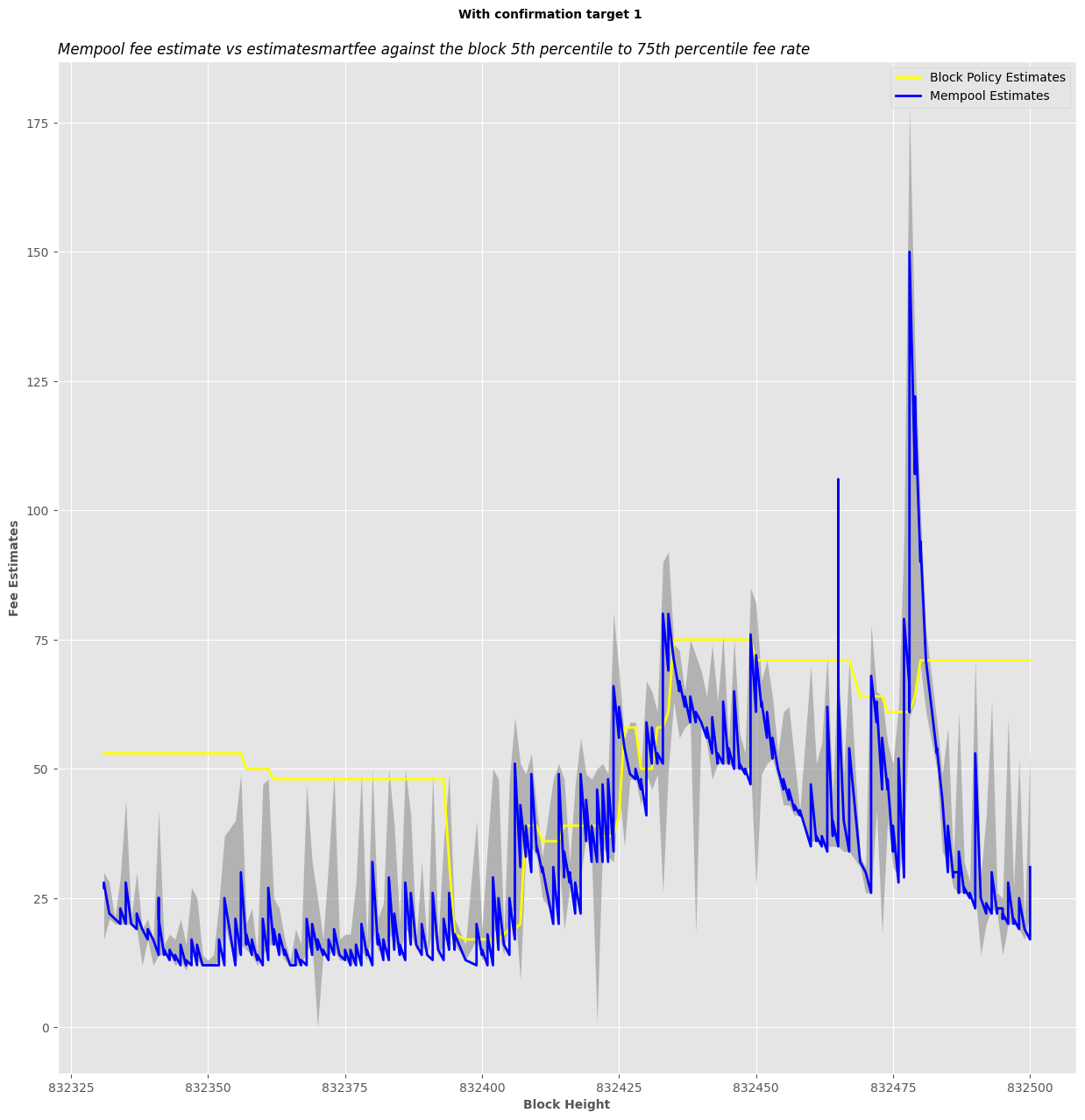
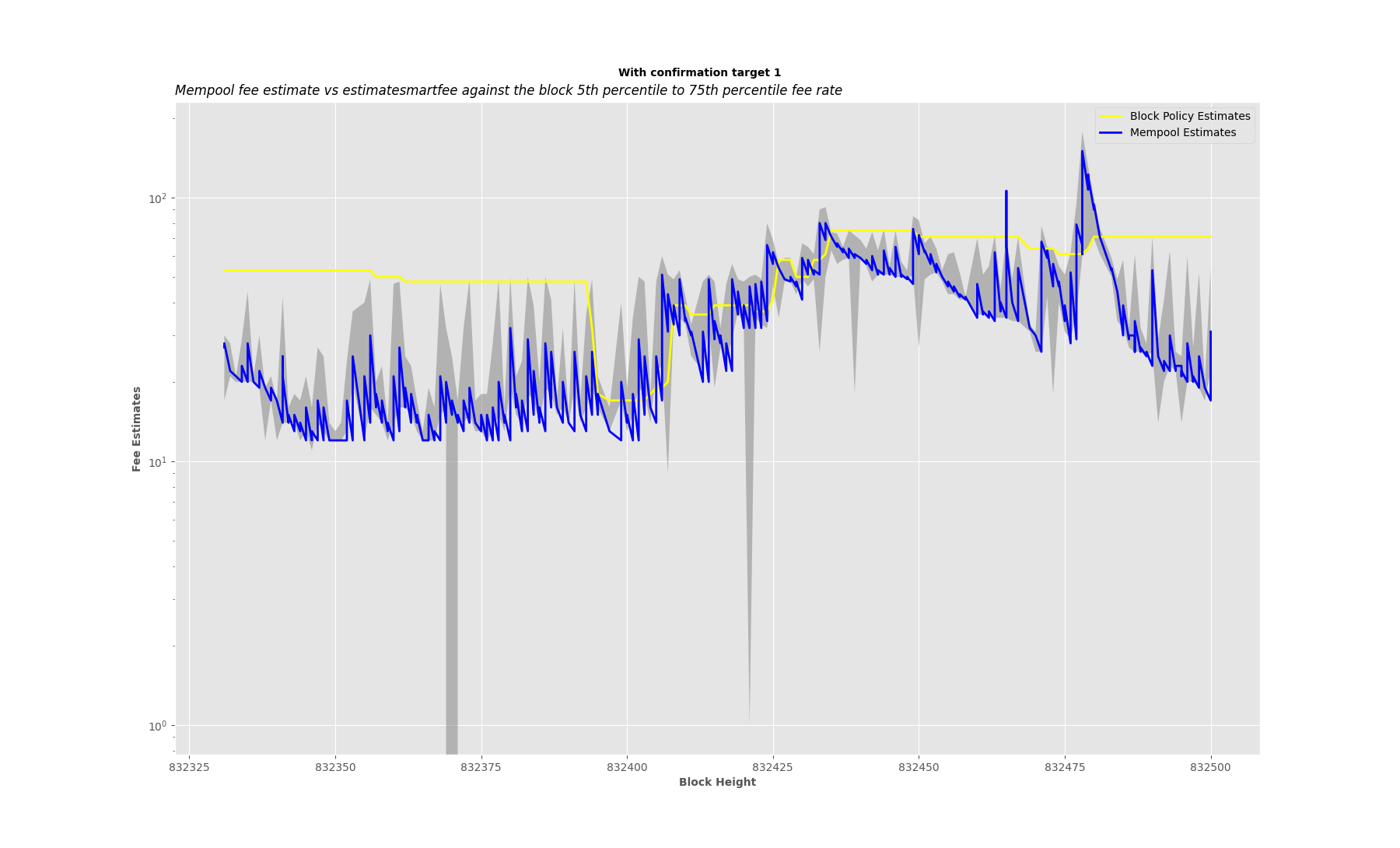
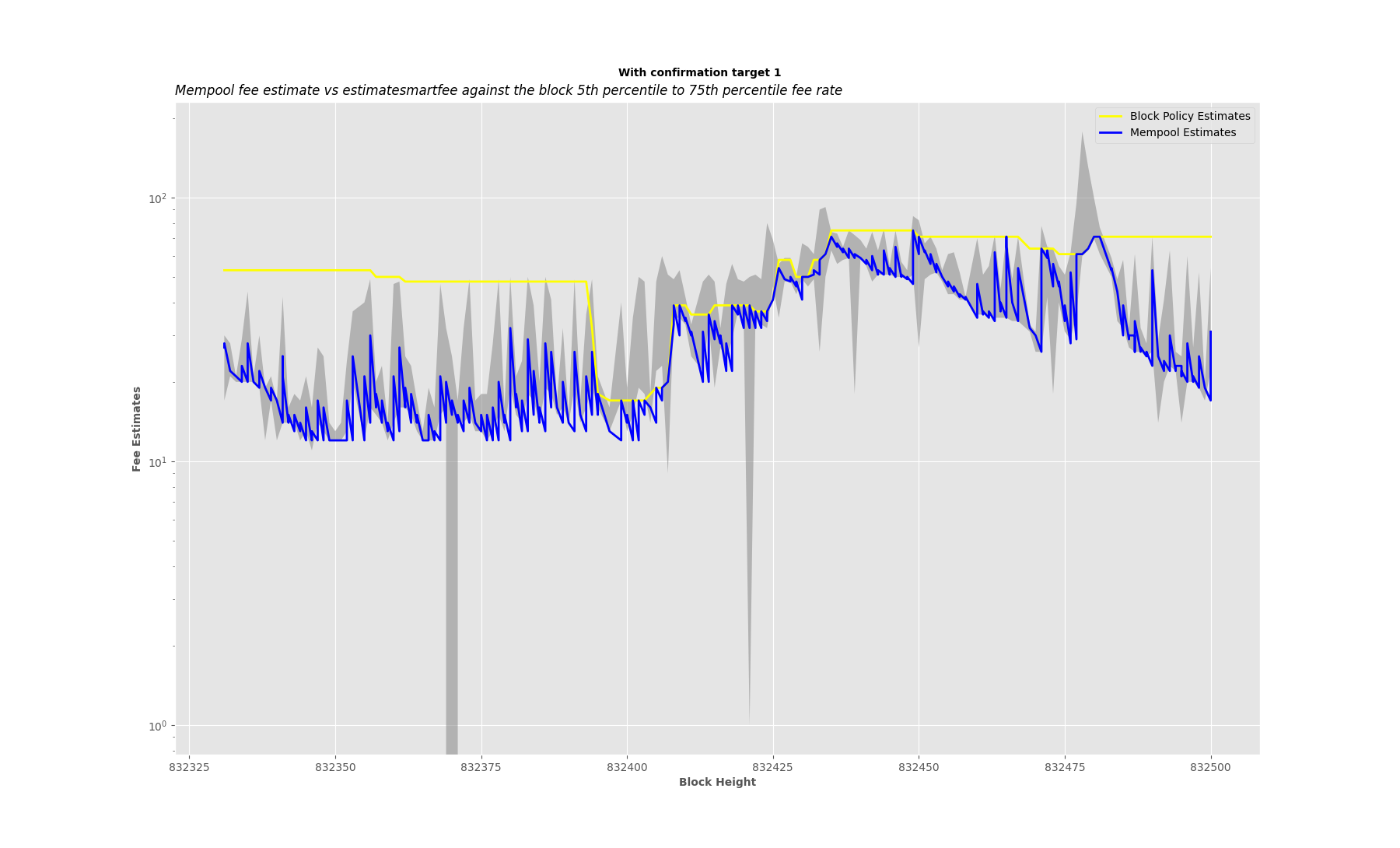
I have been analyzing the disparities between fee estimates of the mempool-based fee estimator without sanity check,
CBlockPolicyEstimator[4], against the confirmed block target median fee rate.
Methodology
- I’ve implemented a mempool-based fee estimator without any sanity check, made it available in an RPC, and schedule a job that logs the fee estimate from mempool,
CBlockPolicyEstimator[4] estimatesmartfee after every one minute with confirmation target 1, then when the target block is confirmed its median and average fee rate are also logged.
My node runs from 832330 to 832453, after that using a simple Python script I filter through my debug.log and collect all the fee estimates and the confirmed block target median and average fee rate to make a comparison.
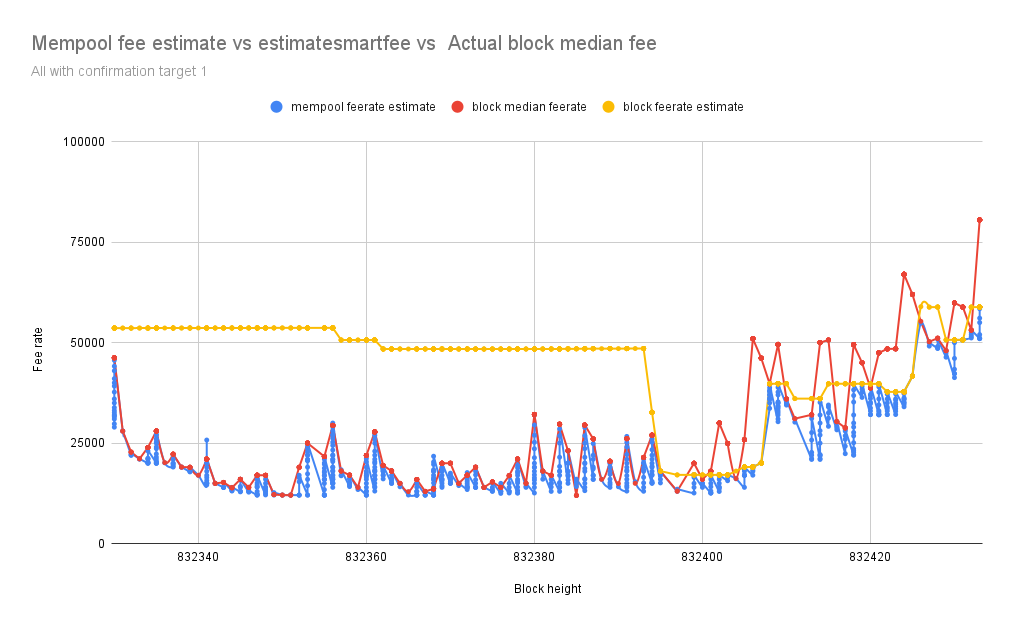
The chart below represents fee estimates with mempool in blue and estimatesmartfee in yellow, and the block median fee rate in red consecutively every one minute from Block 832330 to 832453
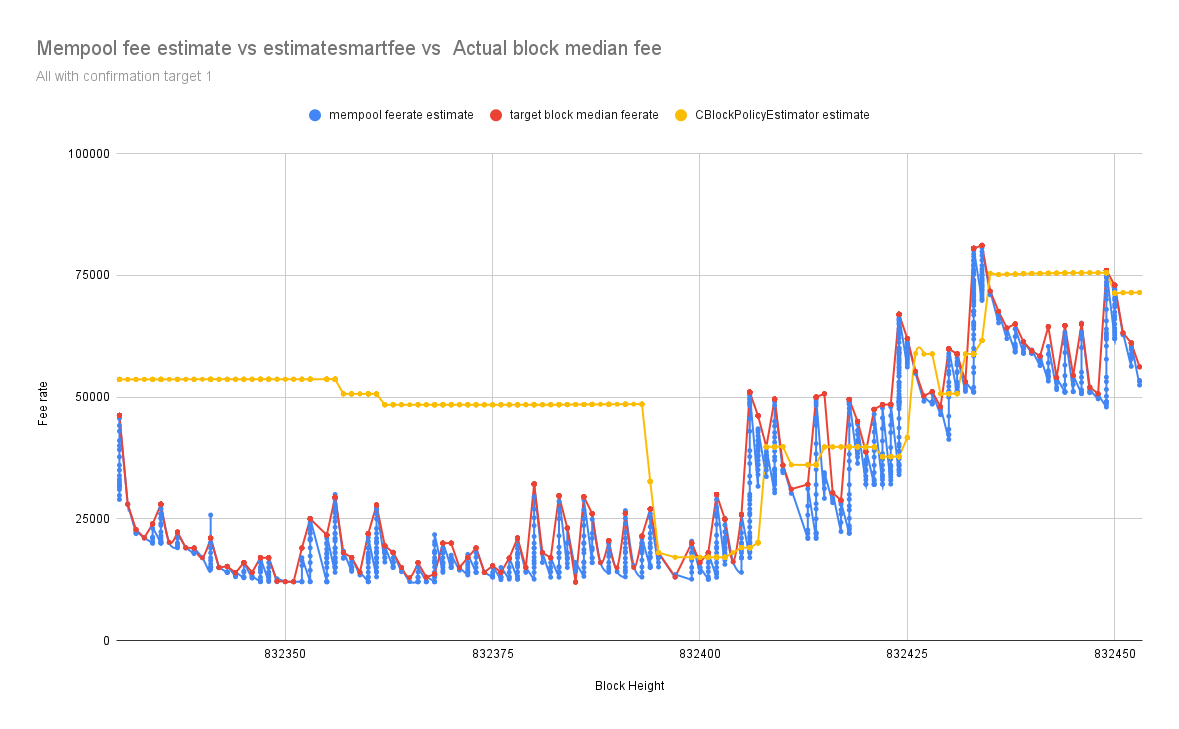
From the data above fee estimation with mempool is closely following the block median fee rate, more accurate than CBlockPolicyEstimator[4] estimatesmartfee.
You can make a copy of the sheet and mess around with the chart data range to see the difference.
- You can also build the branch and call
estimatefeewithmempooland make a comparison with mempool.space and the target block median fee rate that will be logged.
This is a joint work with @willcl-ark , I appreciate @glozow 's input on some of the ideas above.
Thank you for reading.
[0] Percentile
[1] How mining pool generate block templates
[3] bitcoin/src/node/miner.cpp at 71b63195b30b2fa0dff20ebb262ce7566dd5d673 · bitcoin/bitcoin · GitHub
[4] An Introduction to Bitcoin Core Fee Estimation | John Newbery