In An overview of the cluster mempool proposal, I wrote up a description of a new mempool design. As that proposal would change which transactions make it into the mempool under certain circumstances, it raises questions around what effects those changes to relay policy might have on the network, should the proposal be widely adopted.
I attempted to gain some insights into this by simulating the mempool using the current design in Bitcoin Core on data from 2023, and comparing that to a simulation of my prototype cluster mempool implementation (https://github.com/bitcoin/bitcoin/pull/28676) on that same data. In this post, I’ll summarize my findings.
Methodology
Background
I have a patchset to Bitcoin Core that does two things:
- Datalogging: a node running with datalogging enabled will record every block, transaction, header, compact block (etc) received over the network along with a timestamp, and write it to disk.
- Simulation: when running in simulation mode, the networking code is disabled, and for the given target date range, the node will read stored data and play it back through validation (via the
ProcessNewBlockandProcessTransactionhooks in Bitcoin Core). This allows for studying the effect of changes to the mempool or consensus logic on historical blocks and transactions.
My datalogger has been (mostly) running for the past 10 years or so, so I have a lot of historical data that my logging node has seen. Note that there is nothing canonical about my data; when I run my simulations, I am just taking one node’s view of the network into account when doing analysis. However, I believe the data I have should be representative of what other nodes may see as well.
Additional code changes for this study
I patched my cluster mempool prototype implementation with the simulation code described above, and did the same with a recent commit from Bitcoin Core’s master branch. In addition, I made a couple of additional changes to the code:
- Comparing the effects on mining: in both simulations, I inserted a call to
CreateNewBlock()just before each actual block received over the network is delivered by the simulation system. This allows for comparing block templates that would be generated by each implementation, sampled at consistent points in time (which happen to line up with when actual blocks were relayed on the network). - Simulating the effect of a cluster size limit on user behavior: in just the cluster mempool simulation, I modified the transaction processing logic to store transactions that were rejected due to a cluster size limit being hit, and then to try to reprocess all such stored transactions after each block is delivered. (more discussion on this below)
Configuration
- I ran both simulations with
-debug=mempooland-debug=mempoolrej, so that I had logging for every transaction’s acceptance or rejection from the mempool. - I also ran both simulations with
-maxmempool=20000, to effectively unlimit the mempool size so that mempool trimming would not be triggered. This reduced the noice in comparing differences between the simulations, as otherwise we’d have small differences from slightly different mempool minimum fee values that occur because the memory layout/usage of the two implementations differ. - The cluster mempool implementation was run with cluster mempool limits of 100 transactions/101 kvb** transaction size. (Note also that the cluster mempool implementation has no limits on ancestor or descendant counts or sizes.)
Both simulations were run on all the data I recorded in 2023, from Jan 1 to December 31.
Note that I’m presenting statistics from my last run of the cluster mempool simulation, but it took me a few tries to get it right (I had some bugs to fix along the way).
Results
Overall transactions accepted
- Cluster mempool: 151,579,643
- Baseline: 151,561,522 (~0.01% fewer txs)
There are a couple of reasons we see different transactions accepted in each simulation:
- The cluster mempool logic rejects transactions that would create clusters that are too large, but it is more lax than the baseline logic which imposes a limit on ancestor/descendant counts. In 2023, those ancestor/descendant limits caused over 46k txs to be rejected at some point (note that they may have been later accepted in the simulation if they were rebroadcast). Meanwhile, only ~14k transactions were rejected due to a cluster size limit being hit, in the cluster mempool simulation (more on this below).
- The RBF rules enforced in the two simulations are different, but this turned out to produce a negligible effect on the aggregate acceptance numbers here. I’ll discuss the RBF differences in more detail below.
In the aggregate, the absolute differences in accepted transactions is negligible. However, this high level analysis doesn’t answer the question of whether there might be some use cases that are meaningfully affected, which gets lost in the big picture.
Effect of retrying cluster-size-rejected transactions
In a cluster mempool world, we might expect users to respond to a transaction being rejected due to a cluster size limit in a couple of different ways. One is that they might reconstruct their transaction by changing inputs, to try to avoid creating too large of a cluster. However another possibility is that users might just wait and try to rebroadcast their transaction later, after other transactions already in the cluster are confirmed.
(This is the same as what I expect users might do today, should they hit an ancestor or descendant size limit.)
We don’t have a good way to simulate users choosing to reconstruct their transactions in the face of a rejection, but by retrying transactions that were rejected due to cluster size limits, we can model the effectiveness of the wait-and-rebroadcast approach. In particular, we can estimate that transactions which were eventually accepted to the mempool in the simulation would have been minimally affected by a cluster size limit last year, because being accepted to the mempool means that relay would have been successful prior to the transaction being selected by a miner last year.
With that in mind, here are the numbers for cluster size rejections and eventual mempool acceptance on retry:
- Total transactions accepted to cluster mempool in 2023: 151,579,643
- Number of transactions rejected due to cluster limit: 14,358
- Number of these accepted during reprocessing after a block: 10,122 (70%)
So a very small percentage of overall transactions were rejected due to a cluster size limit, and of those, 70% would have been ultimately accepted to the mempool. That gives us a bound of at most 30% of transactions that would have been rejected and not ultimately accepted (note: I didn’t verify that these 30% were all mined, so this is an upper bound).
Economic significance of mempool differences
While we’ve seen that the number of transactions affected by the cluster mempool change is very small, the question remains whether those transactions might be economically significant to the network (and miners who would potentially be missing out on the ability to include them, in a cluster mempool world).
To get a sense of this, we can look at differences in block fees, as determined from running CreateNewBlock() at the same points in time in both simulations, and looking at the distribution of the differences in total fees.
Percentage fee differences
This graph shows the percentage fee difference between the blocks produced by the cluster mempool simulation and the baseline simulation. Each datapoint (x, y) is (block number, (cluster_fees - baseline_fees) / cluster_fees)).

Absolute fee differences
This graph shows the absolute difference in fees (same data as shown above, but the y-values are not normalized by the block fees in the cluster mempool blocks):

(Note: the x-axis is again the block number, just as in the prior graph, but for some reason it rendered as the block height rather than starting at 0.)
Histogram of fee differences
Just to give a sense of how often one implementation outperformed the other, I produced a histogram of the fee differences, ie cluster mempool block fees minus baseline block fees. I discarded the 0 values to avoid skewing the histogram with values where the implementations tied.
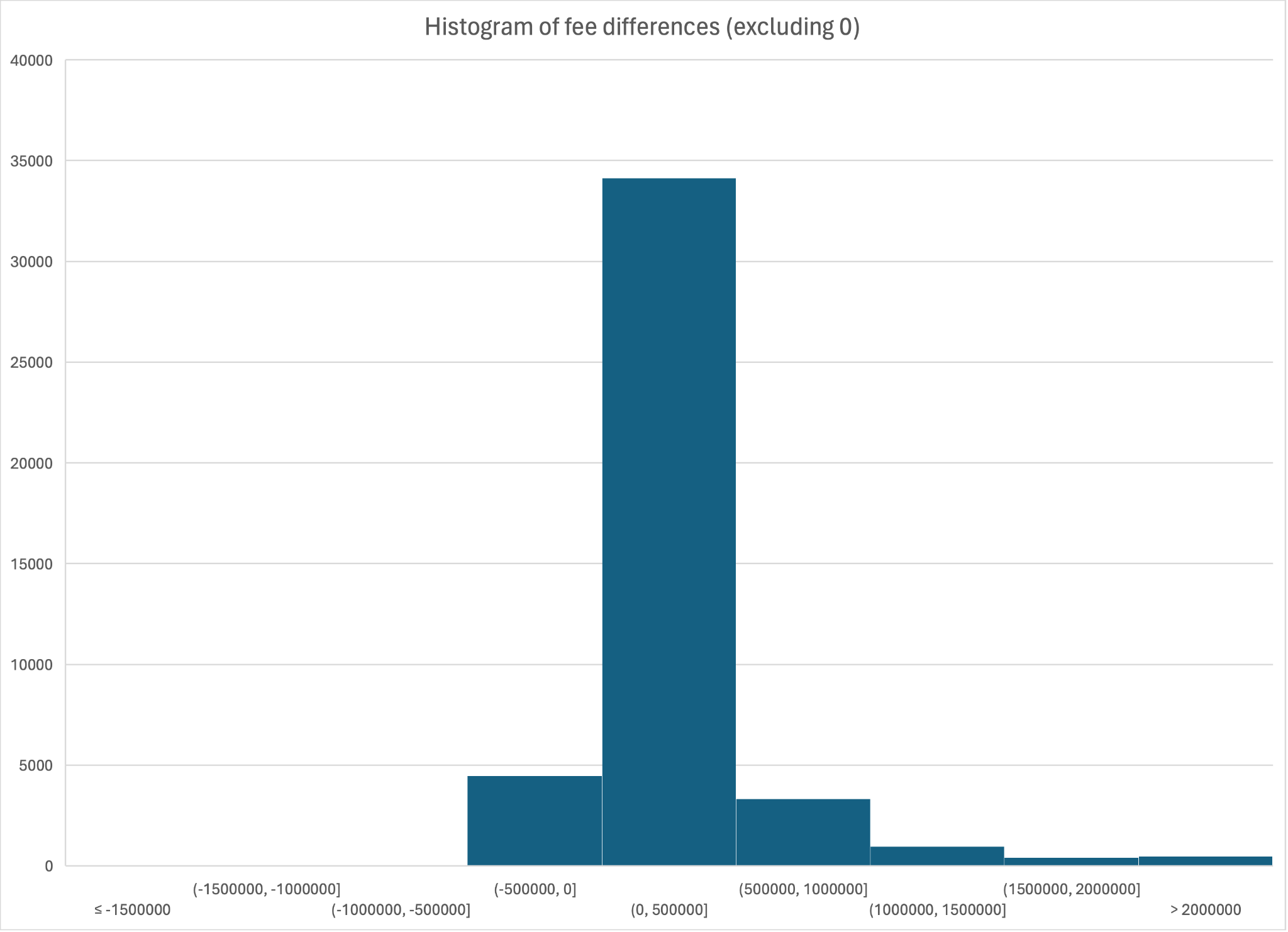
The buckets here are in increments of 500k sats.
Statistics
- Average fee difference (cluster - baseline): 153,615 sats
- Percentage of blocks where cluster was better: 72.8%
- Percentage of blocks where baseline was better: 8.4%
- Maximum amount cluster was better by: 18,246,422 sats
- Maximum amount baseline was better by: 10,299,305 sats
Discussion
Note that these graphs overstate the benefit of cluster mempool. This is for a few reasons:
- If there’s a sort order that is more optimal than what miners were doing in practice last year, this analysis will show persistent differences until the transactions that caused the difference were mined.
- This also conflates two effects: the choice of what to accept to the mempool, and the sort order of what is in the mempool. Cluster mempool gives us differences in both. Of course, we can’t easily tease these apart because it’s not practical to do a more optimal sorting using the legacy mempool.
- Over longer time spans, the differences in sort order don’t matter, as essentially all the same transactions eventually get mined.
However, if we’re trying to answer the question of whether cluster mempool might have a significant negative impact on fees collected in blocks, then it seems to me that there is no evidence of this in the data. While it may be inconclusive as to whether cluster mempool is materially better than baseline based on network activity in 2023, it strikes me as very unlikely that cluster mempool is materially worse.
RBF changes
As a reminder, the cluster mempool RBF rules are centered around whether the feerate diagram of the mempool would improve after the replacement takes place, while Bitcoin Core’s existing RBF rules are roughly what is described in BIP 125 and documented here.
Unlike BIP 125, the proposed RBF rule is focused on the result of a replacement. A tx can be better in theory than in practice: maybe it “should” be accepted based on a theoretical understanding of what should be good for the mempool, but if the resulting feerate diagram is worse for any reason (say, because the linearization algorithm is not optimal), then we’ll reject the replacement.
So, we should wonder:
- Do any quirks arise from doing things this way?
- Does the number of RBFs successfully processed materially change?
- Are there transactions that are rejected in cluster mempool which “should” be accepted?
- Are use cases impacted from users (ab-)using the old rules?
Aggregate effects
To start, we can note the number of total RBF replacements in each simulation:
- Cluster mempool: 3,642,009
- Baseline: 3,641,885
These numbers are nearly identical in aggregate, and the cluster mempool branch was able to process slightly more transactions than the baseline. Certain rules are not enforced in the cluster mempool model, which serve to restrict the number of txs accepted by the baseline model:
- Rule against adding new unconfirmed parents (532 txs rejected for this in baseline)
- Descendant chain limit can be more restrictive than cluster size limit
However, my primary focus in analyzing this data was to try to characterize the replacements which would have been rejected by cluster mempool, but accepted under BIP 125.
Cluster mempool RBF rejections
Why are some replacements rejected only by the cluster mempool rules? There are four reasons that we might reject a replacement in the proposed RBF policy:
- Too many direct conflicts. In my current implementation, there is a limit of 100 direct conflicts that a replacement can have (which bounds the number of clusters that might need to be re-linearized to 100). This is more lax than BIP 125’s rule about the number of conflicts a transaction can have.
- Tx fee must exceed that of conflicts and be able to pay for own relay. This anti-DoS rule is the same as what appears in BIP 125.
- Cluster size limit would be exceeded. We calculate the size of clusters if the replacement succeeds, and if a cluster would be too big, then we reject the replacement.
- Feerate diagram does not improve. This captures the entirety of our new incentive compatibility rule.
Reasons 2 and 4 were the primary reasons we saw RBF attempts rejected in the cluster mempool simulation; since rule 2 is the same as we have currently, I wanted to characterize all the reasons we might see a replacement that passes the BIP 125 rules yet would fail the feerate diagram check.
Fewer than 60 replacement attempts (out of the ~150M accepted transactions last year) fell into this category, and almost all could be characterized as fitting into one of these two scenarios:
-
Merging parents – a transaction conflicted with two or more other transactions which had low fee parents, and the replacement transaction spent all those low fee parents, resulting in a worse mining score than a conflict.
-
Higher feerate child – a transaction conflicted with a tx that had a higher feerate child than the replacement transaction.
I’ll explain each in turn, with an actual example from last year.
Merging parents
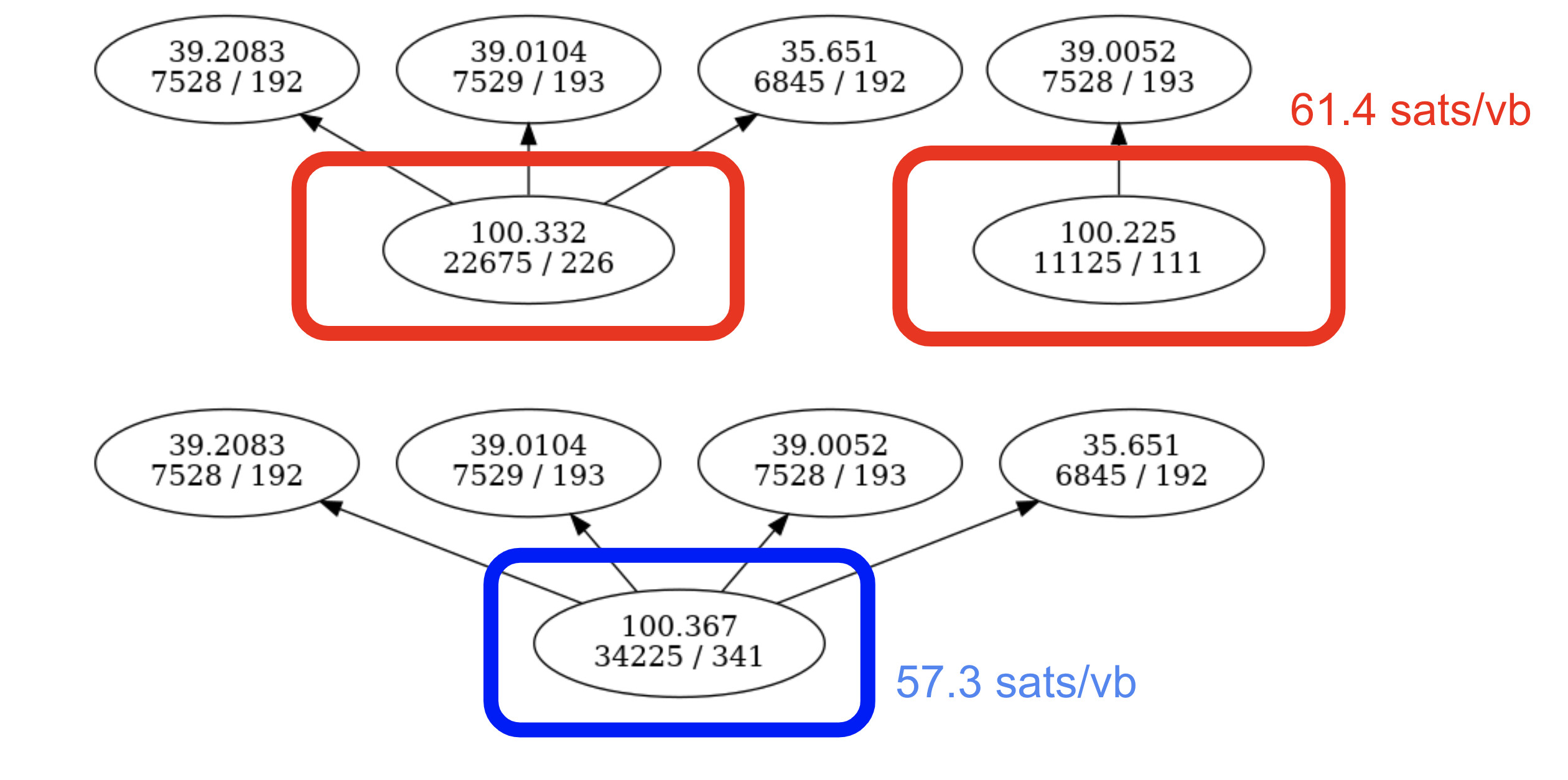
Here, the blue transaction is a replacement that would conflict with the two red transactions. We can see that its parents are the union of the parents of the two transactions already in the mempool, and that as a result its mining score (57.3 sat/vb) is actually less than that of one of the conflicts (61.4 sat/vb), despite the replacement having a higher feerate and higher fee than the transactions it would replace.
In this example, the BIP 125 rules are permitting a replacement that may be making the mempool worse off, by replacing a transaction with a higher mining score with one that has a lower mining score.
Higher feerate child

In this example, the blue transaction would replace both the red transactions, but it only directly conflicts with the parent. Because BIP 125 only requires that a replacement transaction have a higher feerate than its direct conflicts, the feerate rules of BIP 125 are satisfied even though the replacement has a lower feerate than the child that it would also replace.
In fact, the child has a higher mining score than the incoming blue transaction (10.6 vs 9.0 sats/vb), so again the BIP 125 rules here are permitting a replacement that may be making the mempool worse.
It’s tempting to think at this point that the new RBF rules are always just better than BIP 125, in that they differ in cases where BIP 125 would allow the mempool to become theoretically worse. However, there is a caveat to this that is worth flagging.
Replacements can also be rejected due to suboptimal linearizations
Because optimal linearizations are currently only known to be computationally feasible when working on small clusters, we fall back to using heuristics like the ancestor feerate algorithm when linearizing large clusters. As a non-optimal sorting algorithm for clusters, it’s possible that we might have some examples of clusters that would improve if we were using an optimal sort, but actually get worse when using a non-optimal sort.
And indeed in some of my cluster mempool simulations, I occasionally encountered examples like this. Typically the situation would be that a replacement is being attempted where the new transaction has the exact same size and parents as an existing transaction, but with a higher fee. In such situations, it’s obvious that if we simply placed the new transaction in the same spot as the old one, that the mempool would be strictly better.
However, due to quirks in the ancestor feerate algorithm, sometimes we wouldn’t find a strictly better linearization even in such obvious cases, and thus the new RBF logic would reject the replacement. These examples are interesting to think about, because:
- This type of situation will always be possible if we allow for non-optimal cluster linearizations, ie, if we permit cluster sizes to be too big to optimally sort.
- Even though such transactions “ought” to be accepted, they really are (inadvertently) making the mempool worse in some way, by triggering flaws in our linearization code. This highlights that under the existing BIP 125 rules, we are also allowing such replacements which, under the hood, result in worse behavior than we expect.
- Obviously, we’d still like to eliminate all these cases as much as possible, as it’s more optimal for everyone (users and miners) if this doesn’t happen.
In practice, we have linearization techniques (learned from seeing these examples) which will eliminate the specific type of failure that I observed from happening again. However, as a theoretical point, it’s worth noting that this category of example will always exist. So if new use cases emerge that are triggering this type of behavior, then we may want to put in additional work to try to tweak our algorithms to improve linearizations for those use cases.
RBF summary
Overall, the RBF differences between cluster mempool and existing policy were minimal. Where they differed, the proposed new RBF rules were largely protecting the mempool against replacements which were not incentive compatible – a good change. Yet it’s important to also be aware that in theory, we could see replacements prevented that in an ideal world would be accepted, because sometimes seemingly good replacements can trigger suboptimal behavior, which was previously undetected (by BIP 125 policy) but would be detected and prevented in the new rules.
Summary
It seems to me that with cluster size limits of 100 transactions / 101 kvb, and with new RBF rules designed to prevent the mempool feerate diagram from ever worsening, that we wouldn’t really be affecting existing use cases on the network very much, based on last year’s data. An extremely small percentage of transactions would have exercised the new behavior; in the case of transactions which would exceed the new cluster size limits, 70% would have been able to be resubmitted later without affecting when they were ultimately mined.
In the case of RBF, the effect of the rule change is small and beneficial – perhaps the ideal type of change!
And finally, it seems that block construction is unlikely to be any worse, and in my estimation, is actually likely to be better (but this is hard to say definitively).