Over the last few years we’ve started seeing significant divergence in mempool policies, particularly adoption of full replace by fee, various Knots spam filtering options, uncapped datacarrier/OP_RETURN and most recently 0.1sat/vb minfee.
Background
A technical aspect that has influenced those discussions is the impact on compact block relay.
As a quick reminder, it’s fairly important for new blocks to be relayed quickly to other miners: if there are significant delays, that can both (a) increase the orphan rate for smaller miners, leading to higher comparative returns for larger miners, leading to centralisation, and (b) make attacks such as selfish mining easier to perform. Compact block relay, which was released in Bitcoin Core 0.13.0 in August 2016 provides a way to significantly improve block relay speeds, but relies on each node’s mempool making an reasonably accurate prediction of what transactions will be in the next block. When it gets it right, the current tip can be updated without requiring a round-trip over the network, potentially reducing relay time to a third of what it might otherwise be. This effect can be observed in the DSN Block Propagation History charts, driving block propagation times down from around 5s to very close to 0s:
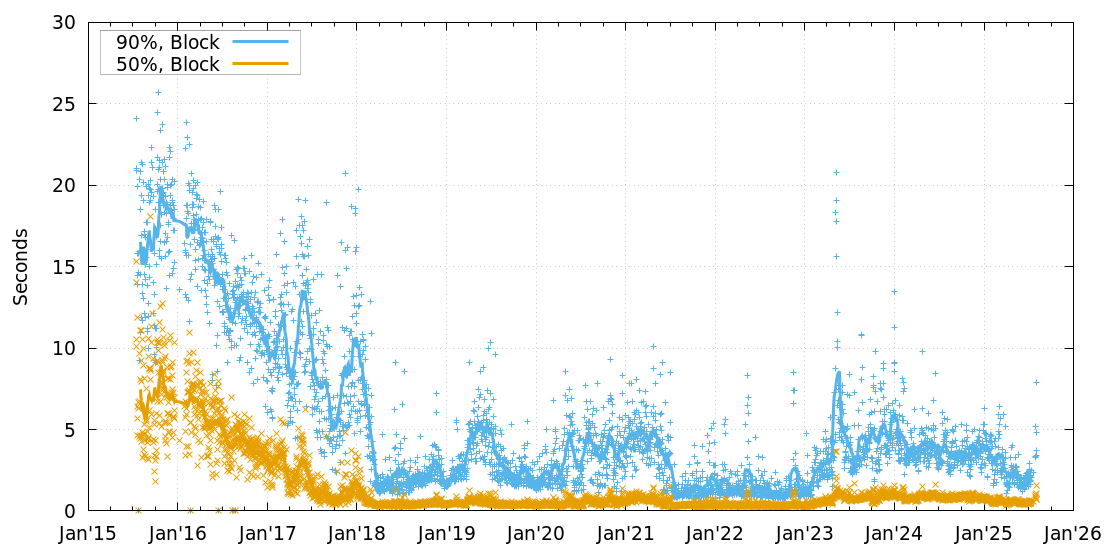
The expected orphan rate if blocks take about 5s to propagate is perhaps 1.2 per day; if they take about 300ms, it’s about once every two weeks, roughly matching observed rates.
The practical impact of the adoption of diverse mempool policies by nodes and miners has been written up in another topic:
Last year, Greg raised the prospect of using weak blocks (including a proof of concept implementation), as one way to mitigate this – that way miners would (optionally) publish shares that didn’t quite hit the proof-of-work target to the p2p network, and peers would be able to see what miners are actually working on, while still benefiting from proof-of-work to limit just how much traffic they have to deal with.
To my mind, relying on proof-of-work has significant drawbacks: it biases towards groups with high hashrate, leading to a lot of repetition; and weak blocks will be spread out randomly across time, so if a miner with 10% hashrate wins the next block, their last weak block may well have been from 7 minutes ago (assuming weak blocks are 1/16th the difficulty of a real block), and thus be missing transactions, and still lead to a round-trip.
Template sharing
An alternative approach that I think could be made to work is simply sharing your block template with your peers. That is:
- you regularly generate a new block template from your mempool,
- you share that template with your peers when they ask for it
- you request your peers send you their template regularly
- you check txs in your peers’ templates, adding them into your mempool if they meet your policy requirements and you didn’t already have them
- if they don’t meet your policy requirements, you keep the transactions in memory anyway, until you get a new template from that peer
- when you attempt to reconstruct a compact block, you use your peers’ templates as a source of transactions in addition to your mempool
This can be done fairly efficiently: using the compact block encoding, sharing a template of 3000 transactions requires a 20kB message, and because sharing templates is not particularly time sensitive, it’s not much of a burden to request the missing transactions. Likewise, it’s not much of a burden to just skip a template entirely if you’re not able to cleanly reconstruct a template because the random numbers chosen give you conflicts.
This approach has a couple of other benefits/properties too.
It means that if you start up a node that either has an empty mempool or just one that’s out of date, it will very quickly be populated with what your peers think are the highest fee paying transactions. That’s beneficial not just for compact block relay, but also if your node is providing templates to miners, either as a pool template node, or as a datum or stratumv2 template provider for an individual miner.
It also automates rebroadcasting transactions that may have dropped from default mempools, once fees have reduced and they get to the top of the mempool. This primarily has privacy benefits – rather than the only person likely to rebroadcast a transaction in that scenario being the sender or recipient, any p2p node with a large enough mempool to have kept it will include the tx in its templates, and those nodes’ peers will rebroadcast the tx when they reconsider it for their mempools.
It also provides a way to query the top of random nodes’ mempools at fairly low cost, which may be useful for either overall analysis of network behaviour, or for detecting tx relay issues (in the event of pinning attacks, eg).
I’ve done a proof of concept of this approach at:
It’s setup to generate a template every 30s and keep the last ten generated templates (as a way of caching recently RBF’ed txs), it only announces templates to peers when all the txs in the template are considered to have been announced to that peer (base on last_inv logic), and it requests templates from outbounds once every 2 minutes. Transactions that failed mempool policies that might succeed later will be retried every so often.
It’s limited in that it will only request templates from outbound/manual peers (to limit the additional memory use to something on the order of 30MB), and would need some cleverer budgeting logic to safely store txs from templates from random inbound connections. It also doesn’t keep track of which transactions are actually in the mempool; doing that would likely make block reconstruction a bit more efficient, and is probably also necessary for any cleverer budgeting logic.
Starting a signet node with an empty mempool (but synced blockchain) looks something like this:
2025-08-05T18:54:58Z [sharetmpl] Generated template for sharing hash=730e806fde65ec561c565bb46a7eaf858dce9603b1d4faf632325f0dabf83424 (1 txs)
2025-08-05T18:54:58Z [net] sending sendtemplate (0 bytes) peer=0
2025-08-05T18:54:58Z [net] received: sendtemplate (0 bytes) peer=0
At startup, we can only create an empty template and negotiate sending templates.
2025-08-05T18:54:58Z [net] sending gettemplate (0 bytes) peer=0
2025-08-05T18:54:58Z [net] received: template (18542 bytes) peer=0
2025-08-05T18:54:58Z [net] sending getblocktxn (3085 bytes) peer=0
2025-08-05T18:54:59Z [net] received: blocktxn (1234572 bytes) peer=0
2025-08-05T18:54:59Z [sharetmpl] Peer 0 sent us compact template 92b0f676a921478106506041b7695534092f7ab7a40a84ef84fda5976526d94c with 3050 transactions
2025-08-05T18:54:59Z [sharetmpl] TemplateMan: 1 in my queue, 1 peer templates, 3052 txs
Then we pretty quickly request a template.
2025-08-05T18:55:28Z [sharetmpl] Generated template for sharing hash=2427faa7ba5bb5ab136ed6ba63c29600a82704b31892d80c2919ea861677f249 (3063 txs)
2025-08-05T18:55:58Z [sharetmpl] Generated template for sharing hash=cf6989e8b1a1fb43422813fd5db984ed0bdbc88301b4e4a0d60cb93e01469004 (3078 txs)
2025-08-05T18:56:28Z [sharetmpl] Generated template for sharing hash=886636973ebfe11de10e6f315d2375fe2b84b30656c5f02badd2f8305ccf84be (3083 txs)
Once we’ve done that, and processed the transactions, our templates quickly become much more useful.
2025-08-05T18:56:58Z [net] sending gettemplate (0 bytes) peer=0
2025-08-05T18:56:58Z [net] received: template (18746 bytes) peer=0
2025-08-05T18:56:58Z [net] sending getblocktxn (61 bytes) peer=0
2025-08-05T18:56:59Z [net] received: blocktxn (9617 bytes) peer=0
2025-08-05T18:56:59Z [sharetmpl] Peer 0 sent us compact template 8d9d768304d48171a7c0daaefb399f6e17a2b939e6321579713ee76467ebf5fa with 26 transactions
2025-08-05T18:56:59Z [sharetmpl] TemplateMan: 5 in my queue, 1 peer templates, 3209 txs
Then the next template from our peer still required some transactions, but much fewer.