For the “Scatter plot of Missing Bytes/Reconstruction Time for a node whose peers don’t prefill”, some of the points have > 1 MiB missing and have reconstruction times at ~100ms. Do you know if these points are with peers with large window sizes? I would think that if that much data has to be sent across and the window sizes are ~14480, reconstruction times would be a bit higher… I’m wondering if you have any ideas on why the reconstruction times are low in those cases?
Unfortunately congestion windows are computed by the sender of a TCP datagram. I think it’s possible for the receiver to estimate the window size by looking at how many bytes are received before the sender stalls until a little bit after sender fires an ack. This would be good data to have for the next measurement, along with your other suggestion about locating the test nodes far apart from one another.
Edit: For the latency formulas, should they include the cost of transmitted data needed to reconstruct in the failure case? I know they are just to form an intuition, but I was also curious about that.
Definitely, thank you for catching this. Though, I don’t think this would affect the criterion since I think the the term would appear in both the prefilling case and the not prefilling case, so it would cancel, but I have to think more about this.
Within DoS limits (maybe a limit of 4 MiB per valid header), temporarily store a per-block cache of prefilled transactions you hear about, increasing the chances that you successfully reconstruct without having to wait for an RTT.
Is this because we have 3 HB peers and we want to combine prefills across them to try and reconstruct?
That’s what I had in mind, my hypothesis is that in the scenario that reconstruction fails on the first announcement, you are likely to receive a second CMPCTBLOCK announcement from another peer before you complete a GETBLOCKTXN roundtrip with the first HB peer, so it would be nice if we could leverage this to increase our chances of reconstruction without a roundtrip.
Random strategy
I originally imagined that each node would prefill a random selection from their prefill set when they can’t fit everything. But, assuming for simplicity that everyone has the same mempool, the probability of reconstructing from multiple prefills will be extremely low, where d is the number of draws (prefilled CMPCTBLOCKS received), n is the total number of missing transactions and k is the number of randomly prefilled transactions drawn in each CMPCTBLOCK, the probability of reconstruction is
This formula, and every other formula in this post makes the following simplifying assumptions, all of which are false in practice, but I suspect that none of the conclusions here change once they are removed: All transactions are equal in size, all nodes will have the same prefill candidate set, all nodes will have the same prefill size.
Derivation
Probability of missing a particular set of transactions
To calculate the probability of M_i, the event where a given transaction with index i is missing after drawing k many transactions from a pool of n transactions we want to know the proportion of ways to choose k from n that exclude 1 transaction from n, and the number of ways to choose k from n that excludes some member of n is equal to the number of ways to choose k from n-1, so:
Likewise if you want to know the probability that two given transactions, i, j, are excluded:
If we get to draw twice (d=2), the probability that i, j are missing after both draws is the probability that the event happens twice in a row, so:
And more generally:
And with multiple draws:
Probability of missing any set of transactions of a given size
In our case, all sets of single transactions are just as likely to be missing, and all sets of two transactions are just as likely to be missing, and so on.
We can formulate the count of combinations where any 1 transaction is excluded (\sum _{i=1}^{n}|M_{i}|) as the number of unique sets of one transaction, times the count of combinations where a given set of one is excluded:
As a probability:
Having multiple draws, d the probability becomes:
The count of combinations where any 2 transactions are excluded (\sum _{1\leqslant i<j\leqslant n}|M_{i}\cap M_{j}|) is the number of unique sets of two transactions multiplied by the count of combinations where a given set of two is excluded:
Probability:
More generally:
And with multiple draws d:
Probability of missing any set of transactions of any size
The probability of missing any set of any size is equivalent to the sum of probabilities of missing sets of each size, minus the overlaps, since in some of the events where we’re missing one transaction we’ll also miss two or more, and etc. For a formula for this we can use the Inclusion-exclusion principle:
Inclusion/exclusion principle explanation
This explanation and the graphic below are equivalent.
In plain speech, the count of events in A or B or C is the count of events in A, plus the count of events B, plus the count of events in C, so…
¡But!, this overcounts, since any event that is in both A and B (A \cap B) is counted twice, similarly with A \cap C and B \cap C, let’s deal with the intersections of two…
But, we undercounted, since |A|+|B|+|C| counts the events in A\cap B\cap C three times, but |A\cap B|+|A\cap C|+|B\cap C| also counts them three times since any event in all three is in any two, so we have to add them back…
(No but’s left.)
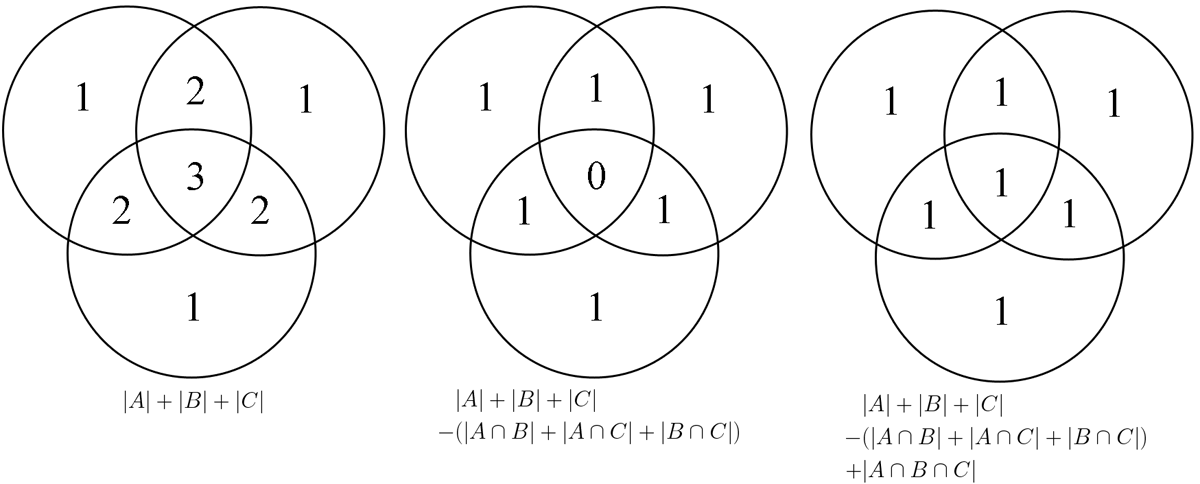
More generally:
And an almost identical expression for probabilities of events:
End Derivation
Applying the inclusion-exclusion formula to the result obtained above:
Plugging in an example, if n = 100, k = 80 and d = 2:
P(\text{reconstruction}) = 0.66\%
Script for calculating
import math
# missing transactions needed for reconstruction
n = 100
# prefills per cmpctblock
k = 80
# number of cmpctblock messages received
d = 2
def p_one_or_more_missing(n, k, d):
assert k > 0 and n > 0 and d > 0 and k < n
# the greatest m for which n - m >= k
m_max = n - k
return sum(
(-1)**(m + 1) * math.comb(n, m) * (math.comb(n - m, k) / math.comb(n, k))**d
for m in range(1, m_max + 1)
)
p_reconstruction = 1 - p_one_or_more_missing(n, k, d)
print(f"P(reconstruction) = {p_reconstruction * 100:.4f}%")
Sliding window strategy
A better strategy was suggested in an offline discussion by @hodlinator which the following is a variation of:
Each prefiller selects a random offset i from the start of their prefill set, and prefills up to the window limit, looping around if they reach the end.
When d = 2
Assuming that all peers have the same prefill set N, for d=2, the probability of reconstruction is:
(Where m_1 = n-k, the size of the missing transaction set after one draw.)
where
Derivation:
Since we continue from the beginning (N_1) of the missing transaction set N when we reach the last transaction N_n: All subscripts i in N_i are i \mod{n} as in N_{(i \mod{n})}. So N_n might also be written N_0.
Note that if we start at some index N_i and take x transactions, we’ll get up to N_{i+x-1} and not N_{i+x} since we have to count taking N_i.
The “missing set” is the transactions that a node is still missing after one or more prefills. If n (|N| or size of the prefill candidate set or number of transactions in the block missing from mempool) is greater than k (the prefill size measured in transactions), than the missing set has a size m=n-k.
At any time, the missing set will be a continuous sequence of transactions from the prefill candidate set N uninterrupted by any prefilled transactions, as long as no prefiller’s k is less than any other prefiller’s m=n-k, since after the first draw the missing set is continuous, and the only way to create a gap in the continuous missing transaction sequence is to pick a transaction in the missing sequence, but not reach the end of the missing sequence, which is not possible if k > m. This is fine to assume for now, since for this formula we are assuming that every node has the same k and the same n.
As long as the missing set is continuous, and k < n (if not, success is inevitable) and k \geq m (if not, success is impossible) the size of the set S of initial transactions for our prefill that will succeed:
Since:
Beginning with the case when k, the prefill set size, and m, the missing set size, are equal, there is only one way to succeed (|S| = 1), by starting the prefill at the first member of the missing set (N_i = M_1): No other value of i will work as long as k < n, since if we advance i one forward, we will miss the first member of the missing set (M_1). If we didn’t miss the first member of the missing set, then we have just reached N_i-1 starting from N_i and advancing to N_{i+k-1}, meaning that:
so
But, we said that k < n, so this is absurd.
Likewise, if we retreat i one back, we will miss the last member of the missing set M_m
thus
If we start at N_{i-1} and draw k == m as supposed:
We will only reach N_{i+m-2} = M_{m-1}.
Likewise, if k = m + 1, we still can not advance the starting transaction even one forward from N_i = M_m, for the same argument as put forth above, summarized: as long as k < n (in which circumstance the prefill would succeed anyways), we will not reach the transaction just before the one we started with, so we will fail.
But, we can now advance one further back, starting at N_{i-1} where N_{i} = M_1, since:
If we start at N_{i-1} and draw k many transactions:
But, since:
It follows that:
But,
So we reached M_m starting at N_{i-1} with k = m + 1.
For the same reasons, if we made k = m + 2, there would be one more way, (totalling three) to succeed.
Since starting at k=m, |S| = 1, and for each increment k grows by 1, |S| grows by 1:
And since the probability of success P_{\text{reconstruction}} = \frac{|S|}{n}:
And simplifying the bounds for this formula, for two draws, if k < m on the second draw, then n \leq 2k, so k < m whenever:
k < n \leq 2k
Also:
where m is the number of transactions missing after the previous prefills. From this we also know the size of the set of transaction indexes that result in failure F:
End derivation
Taking the same example as above, where n = 100, k = 80, d = 2:
When d = 3
For d = 3 (we receive a CMPCTBLOCK from all 3 of our HB peers), the formula is different:
where m_1 = n-k.
Derivation
Not very rigorous, but this is my argument, you probably need to read the derivation for d=2 to follow,
Looking up to what we proved in derivation of the previous formula:
so
On the third draw, m varies depending on what was selected for the second draw. In the worst case, if the same i is selected as the starting index in the first prefill and the second, m=n-k. Similarly |F| is unchanged, the second draw has not reduced the number of ways to fail. But every other possible i on the 2nd prefill will remove some transactions from the missing set M, and F will shrink as a result, since |F|=n - k + m - 1. So, when M loses a member, F loses a member, and vice versa.
Also note that after one draw, |F| = 2m-1, so |F| will always be an odd number after one draw.
Let’s take an example, n = 10, k=7, if the first prefill chooses i=1, then M = \{8, 9, 10\} will be missing, the set of i for which reconstruction will fail on the second draw are F = \{1, 2, 3, 9, 10\} (|F|=2(3)-1=5). If the second draw is the same as the first (i=1), the situation doesn’t change, the missing set is unchanged, M = \{8, 9, 10\}.
But, if the second draw was e.g. i=2, 8 is removed from M, so 9 (and only 9) is removed from the failure set. Likewise, if the second draw was 10, 3 would no longer be a failure condition. In both of these cases one transaction is removed from M, so |F| shrinks by 1.
Similarly, for both i=3 and i=9, two members of the missing set are removed (\{8, 9\} and \{9, 10\} respectively) so in each case, there are two fewer ways to fail.
I think this could be made more rigorous, but I make the argument in a soft and squishy way:
As argued above, the missing set will always be continuous. And if m \geq 2 there will be two ways to remove exactly 1 member from the missing set. Since, you can either start at the last missing transaction M_m and remove that transaction, or you pick some other index i which ends on the first transaction of the missing set N_{i + k -1} = M_1. Any other i will either remove more members from M than 1 or fail to remove 1. If m = 2, then there are |S| as given above ways to remove 2 members.
Likewise for m \geq 3 there are exactly two N_i in N that will remove two members from M, and so on.
This is all with the notable exception stated above, that there is one way for the missing set to remain unchanged on the second draw if n \leq 2k, which is to pick the same index as before.
Please note, I am using m_1 as shorthand for n-k OR m after 1 draw in the following formulas, this is because m is varying.
And so, to count the total number of ways to fail that are removed (r) if the 2nd draw was favorable, there are two ways for it to be lesser by one, two ways for it to be less by two, and so on until m-1:
If we assumed that the number of ways to fail was always maximally bad after the 2nd draw, no matter what it was, the number of ways to fail on the 3rd draw would be (2m_1-1)^2. But, if we take into account the fact that some ways to fail are removed:
And this can be simplified since r is the sum of an arithmetic series:
So (where m_1 = n-k)
and
End derivation
Using the same example again, n = 100, k = 80, d = 3: