An interactive/modifiable version of all the data and plots are in a jupyter notebook here: https://davidgumberg.github.io/logkicker/lab/index.html?path=2025-07-11-first-report%2FPrefilling.ipynb
Summary
I connected two Bitcoin Core nodes running on mainnet, one prefilling transactions to a node that only received CMPCTBLOCK announcements from its prefilling peer. Even though the intended effects of prefilling transactions are network-wide, and it would be nice to have some more complicated topologies and scenarios tested in e.g. Warnet, this basic setup can be used to validate some of the basic assumptions of the effects of prefilling:
- Does prefilling work to prevent failed block reconstructions that otherwise require
GETBLOCKTXN->BLOCKTXN roundtrips, irrespective of the cost of prefilling?
- Does prefilling result in a net reduction on block propagation times?
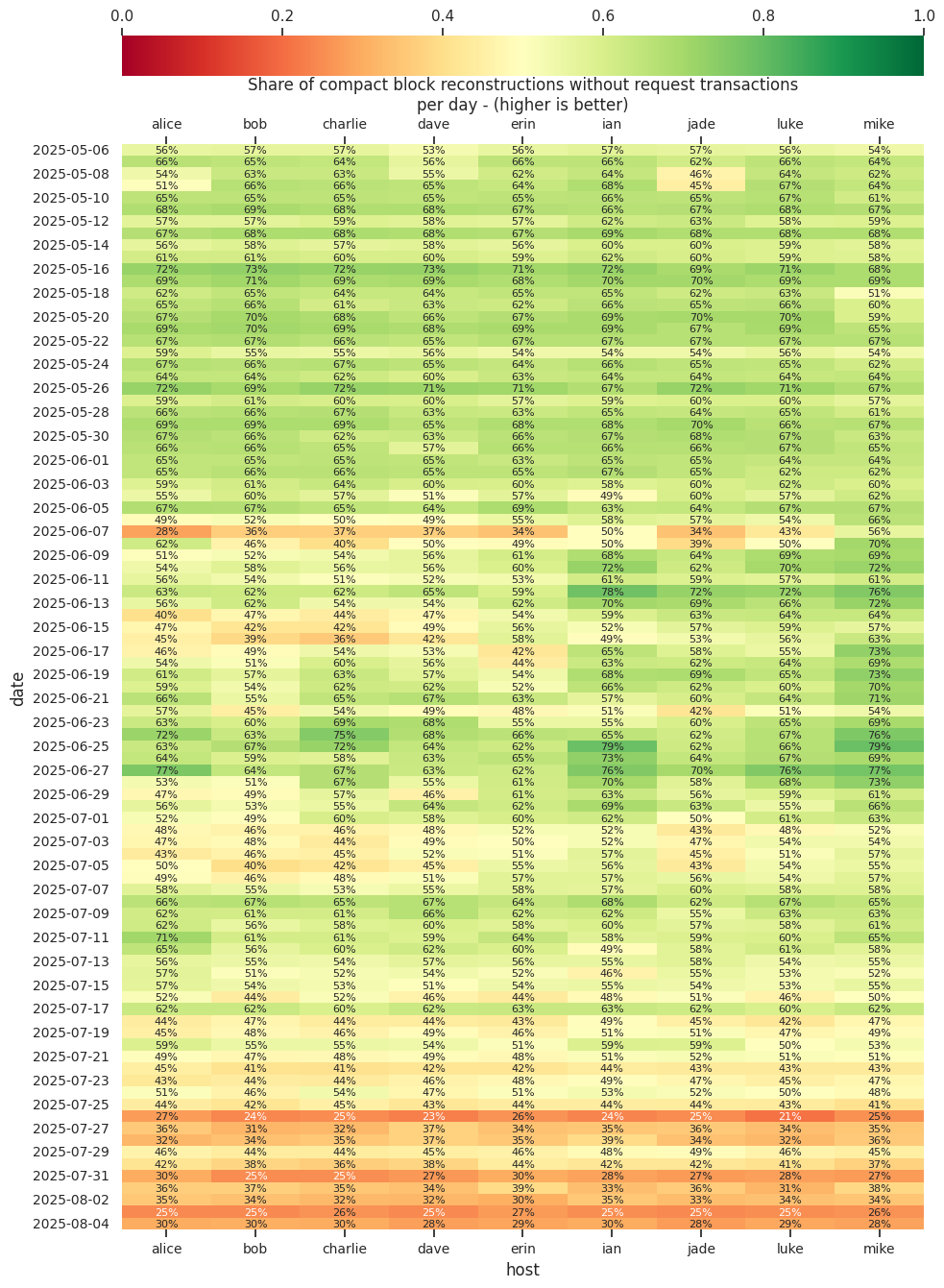
The results indicate that the answer to 1. is definitively yes. The metric used by 0xB10C/2025-03-prefill-compactblocks of prefilling the transactions we were missing from our mempool when performing block reconstruction resulted in an observed reconstruction rate of 98.25% for a node receiving prefilled CMPCTBLOCK announcements when both the prefilling node and the prefill-receiving node are running similar builds of Bitcoin Core, compared to the observed reconstruction rate on a node not receiving prefilled blocks of of 61.81%. Some of those prefills, as pointed out by @Crypt-iQ and @gmaxwell above, exceeded the TCP window, and likely resulted in an additional round-trip, negating the benefit of prefilling. But, in my measurements, 85.78% of the prefills would have fit in the partially occupied TCP window a prefilling node sent the CMPCTBLOCK’s in. Projecting out, these measurements indicate that if all Bitcoin Core nodes had been prefilling during the period which I measured data, the reconstruction rate would have been 93.07% and we can likely do better taking advantage of the fact, pointed out by @andrewtoth above that similar peers will likely have similar vExtraTxn.
I think the following improvements should be made to 0xB10C/2025-03-prefill-compactblocks:
Definitely:
- Only prefill up to the next TCP window boundary.
- Always insert candidates from
vExtraTxn last.
Maybe:
- Within DoS limits (maybe a limit of 4 MiB per valid header), temporarily store a per-block cache of prefilled transactions you hear about, increasing the chances that you successfully reconstruct without having to wait for an RTT.
- If the send window can’t fit all of the prefill candidates, prefill a random selection of candidates, always prefilling transactions not in
vExtraTxn first.
Future investigations should:
- Use prefill-receiving nodes to measure the amount of duplicate / redundant data in the prefill.
- Use two peers with stable and high (maybe artificial?) latencies to easily estimate the number of round-trips that messages take to pass between them, there is also probably external tooling that can measure this.
- Measure / reason about effects of prefilling at a distance of more than one hop.
- Measure data about the
GETBLOCKTXN messages that a prefilling node receives from random peers.
Latency and Bandwidth
Feel free to skip the math in this section or to skip reading this section entirely.
Taking a simplified view, the latency for a receiver to hear an unsolicited message (the scenario we care about in block relay) consists of
transmission delay plus propagation delay:
\text{Latency} \approx \frac{\text{Data}}{\text{Bandwidth}} + \sim{\frac{1}{2}} * \text{Round-trip time}
Any time compact block reconstruction fails because the receiver was missing transactions, an additional round-trip-time (RTT) of requesting missing transactions and receiving them (GETBLOCKTXN->BLOCKTXN) must be paid in order to complete reconstruction, but at this point the amount of data that needs to be transmitted for reconstruction to succeed does not change. Where f is the probability for a block to fail reconstruction:
\text{Latency} \approx \frac{\text{Data}}{\text{Bandwidth}} + \sim{\frac{1}{2}}\text{RTT} + f * \text{RTT}
If we had perfect information about the transactions our peer will be missing, we should always send these along with the block announcements since we will pay basically the same transmission delay, minus the unnecessary round-trip. If we don’t have perfect information, then the worst we can do is send transactions which our peer already knew about, while not sending them transactions they didn’t know about, incurring the RTT anyways, plus the transmission time of the redundant data. Let’s say we send p extra prefill bytes, with each byte having a probability n of being redundant and prefilling p bytes gets us a reconstruction failure probability of f_{p}, then:
\text{Latency}_\text{Prefilling} \approx \frac{\text{Data}}{\text{Bandwidth}} + \frac{p * n}{\text{Bandwidth}} + \sim{\frac{1}{2}}\text{RTT} + f_p * \text{RTT}
Criterion for deciding if prefilling is advantageous
In order for prefilling latency to be better than or equal to no-prefilling latency, the following inequality must be satisfied:
\frac{p * n}{\text{Bandwidth}*\text{RTT}} \leq f_0 - f_p
Derivation
If latency while prefilling is less than or equal to latency without prefilling, where b is bandwidth, r is the RTT, d is the size of the CMPCTBLOCK without prefill, p is the size of the prefill, and f_p is the reconstruction failure rate at a given prefill size p:
\frac{d}{b} + \frac{pn}{b} + \frac{1}{2}r + {f_p}{r} \leq \frac{d}{b} + \frac{1}{2}r + {f_0}{r}
Subtracting the common terms \frac{d}{b} and \frac{1}{2}r from both sides:
\frac{pn}{b} + {f_p}{r} \leq {f_0}{r}
Subtracting {f_p}{r} from both sides:
\frac{pn}{b} \leq {f_0}{r} - {f_p}{r}
Dividing both sides by r:
\frac{pn}{{b} {r}} \leq {f_0} - {f_p}
If we plug in some example values, prefilling 10KiB with a bandwidth of 5 MiB/s and an RTT of 50ms (.050s) and use a worst case n of 1
\frac{10\text{KiB}*1}{5 \text{MiB/s} * 0.050\text{s}} = 0.039
In this case, if prefilling improves reconstruction rates by at least 3.9% it is definitely better than not prefilling.
Latency Cost of Prefilling
And we can quantify the latency cost of prefilling over not prefilling as:
\text{Latency}_\text{Prefilling} - \text{Latency}_\text{Not prefilling} = \frac{p*n}{\text{Bandwidth}} - r(f_0 - f_p)
TCP windows and the costs of prefilling.
But, the use of TCP in the Bitcoin P2P protocol complicates this, because a sender will not send data exceeding the TCP window size in a single round-trip. Instead, they will send up to the window size in data, wait for an ACK from the receiver, and then send up to window bytes after the data which was ACKed. That means that if we exceed a single TCP window, we will have to pay an additional RTT in propagation latency (and a little bit of transmission latency for the overhead). And for each additional window we overflow, we will pay another RTT:
\text{TCP Latency} \approx \frac{\text{Data}}{\text{Bandwidth}} + \sim{\frac{1}{2}}\text{RTT} + f * \text{RTT} + \lfloor{\frac{\text{Data}}{\text{Window Size}}}\rfloor\text{RTT}
Note \lfloor a \rfloor meaning std::floor(a)
Doing a similar dance as above, where p is the prefill size and f_p is the probability of reconstruction failure at prefill size p, and n is the probability of a prefill byte being redundant:
\frac{p*n}{\text{Bandwidth}*\text{RTT}} \leq f_0 - f_p + \lfloor{\frac{\text{Data}}{\text{Window Size}}}\rfloor - \lfloor{\frac{\text{Data}+p}{\text{Window Size}}}\rfloor
The “TCP window” is the smaller of two values: the receiver advertised window (rwnd) and the sender-calculated congestion window (cwnd).
Overflowing current TCP window is always worse than doing nothing
The above formula establishes as a rule something which might have been intuited, that if the prefill causes us to exceed the current TCP window, then we will always do worse than if we hadn’t prefilled, since:
- f_0 - f_p \leq 1 since the smallest number f_0 can be is 0, and the largest number f_p can be is 1.
- \lfloor{\frac{\text{Data}}{\text{Window Size}}}\rfloor - \lfloor{\frac{\text{Data}+p}{\text{Window Size}}}\rfloor \leq -1 if the prefill overflows the current partially filled TCP window.
- If a \leq 1 and b \leq -1, then a + b \leq 0, so the right hand side of the formula is \leq 0.
- The left hand side of the equation will always be \geq 0, since none of the variables on the left side can ever be negative.
- If lhs \geq 0 and 0 \geq rhs, then lhs \geq rhs, so the left hand side will never be less than the right hand side, therefore prefilling will never be beneficial.
But, if we bound our prefill p so that we never increase the number of TCP windows used, i.e.: \lfloor{\frac{\text{Data}}{\text{Window Size}}}\rfloor - \lfloor{\frac{\text{Data}+p}{\text{Window Size}}}\rfloor = 0 which, I believe is easy to do, we can use the exact same formula as above to decide whether or not prefilling is effective:
\frac{p * n}{\text{Bandwidth}*\text{RTT}} \leq f_0 - f_p
Complication: TCP Retransmission
So far, I have assumed perfectly reliable networks and this isn’t always the case, packets get lost, and in TCP that means waiting for a timeout, and then retransmitting. But, I believe the problem above I’ve described in relation to prefilling is very similar to the problem that the designers of TCP had in selecting a static window size, and later, dynamic window sizes through congestion control algorithms like those described in RFC 5681 and RFC 9438. Instead of the probability that a block reconstruction will fail, they deal with the probability that a packet will not arrive, in both cases, the consequence is an additional round-trip, and a core question is whether the marginal value of potentially saving a round-trip by packing in more data is worth the risk that retransmission will be necessary anyways. The analogy is imperfect, as there are many more concerns that TCP congestion control algorithms deal with, but I argue that the node can outsource the question: “How large of a message can we send and reasonably expect everything to arrive?” to its operating system’s congestion control implementation.
Complication: Cost of Bandwidth
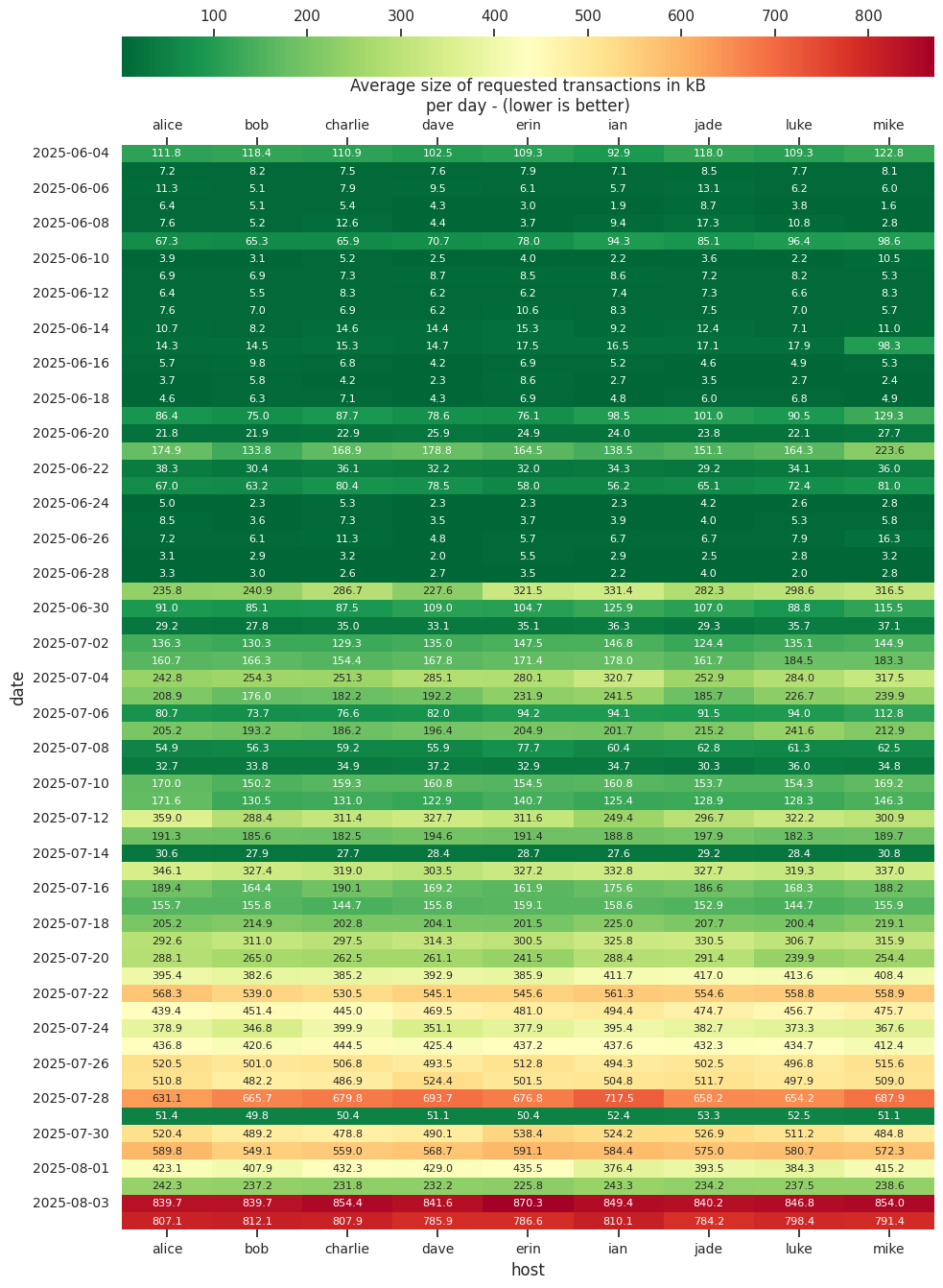
In all of the above, I have assumed the cost of using bandwidth is 0 outside of the latency cost. I’ve done this because I believe the cost of the redundant transactions sent in compact block prefills is negligible, the data I measured below suggests that prefills will be on the order of ~20KiB, so worst case monthly bandwidth usage of prefilling, assuming every byte is redundant and did not need to be sent, and that you always receive a prefilled CMPCTBLOCK from three HB peers, is ~300 MiB. (3 HB Peers * 20 KiB * 6 * 24 * 31)
Takeaways
I don’t think proving that the above inequality being satisfied is necessary for a prefilling solution, what I think it’s useful for is building an intuition of the problem, and setting theoretical boundaries on how effective prefilling needs to be to be worth it.
- Nodes are likelier to suffer rather than benefit from prefilling that have smaller Bandwidth * RTT (See Bandwidth-delay product (BDP)) connections: e.g. nodes with low bandwidth and low ping. And nodes that have connections with large BDP’s are likelier to benefit, e.g. high-bandwidth, high-latency connections(“Long Fat Networks” as described in RFC 7323)
- If the redundant broadcast probability n is zero, prefilling is always worth it.
Data
The data was all taken from debug.log’s generated by the nodes and parsed with this python script: logkicker/compactblocks/logsparser.py at 285034d6833e34dfcb058ce37b30affede0333be · davidgumberg/logkicker · GitHub
CSV’s from the data collected can be found here: logkicker/compactblocks/2025-07-11-first-report at main · davidgumberg/logkicker · GitHub
Summary
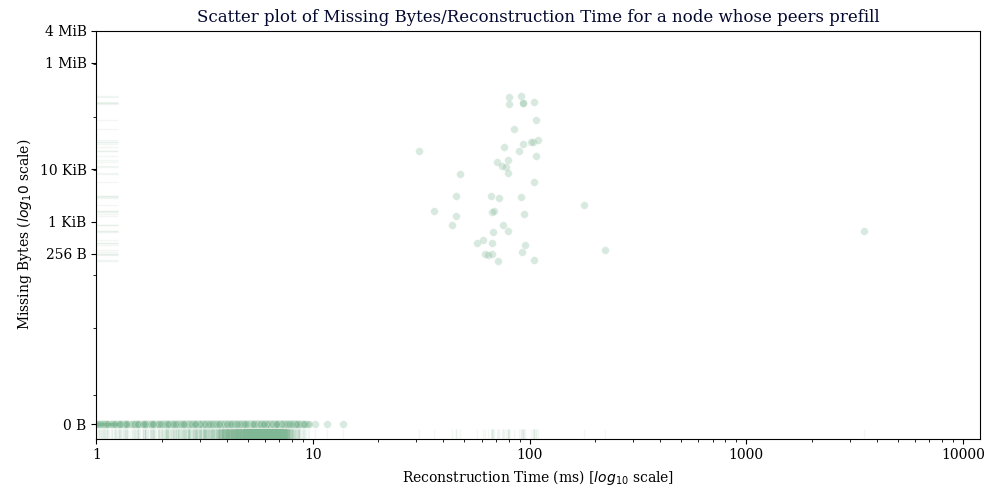
The node receiving not prefilled blocks had a reconstruction rate of 61.81%, the node receiving prefilled blocks had a reconstruction rate of 98.25%, but only 85.78% of those would have fit in the current TCP window of the CMPCTBLOCK being announced, so projecting from those two figures, 93.07% of blocks could have been reconstructed without an additional TCP round trip. The vast majority of TCP windows observed were around ~15KiB. For a lot of the data around prefills, the averages are massive because of a few extreme outliers, but the vast majority of the time, a very small amount of prefill data is needed to prevent a GETBLOCKTXN->BLOCKTXN round trip, 65% of blocks observed needed 1KiB or less of prefill.
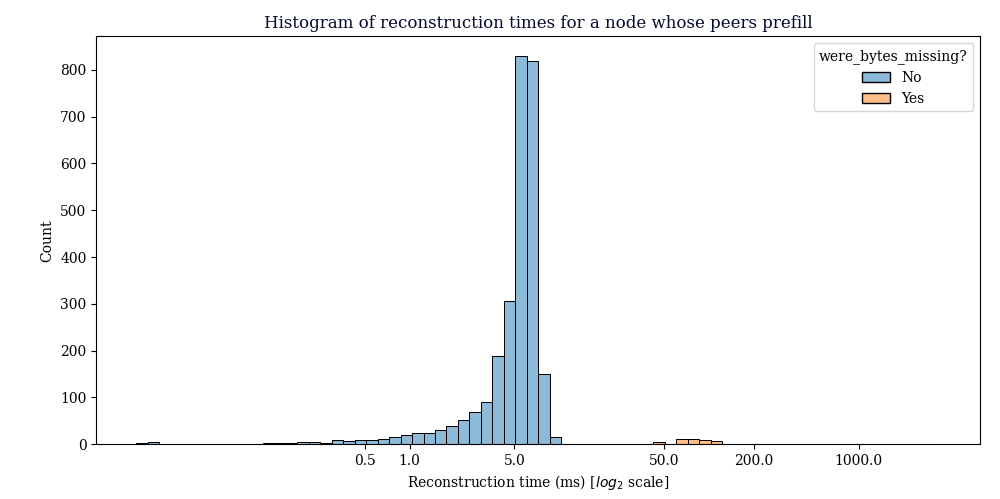
Prefill-Receiving Node: stats on CMPCTBLOCK’s received
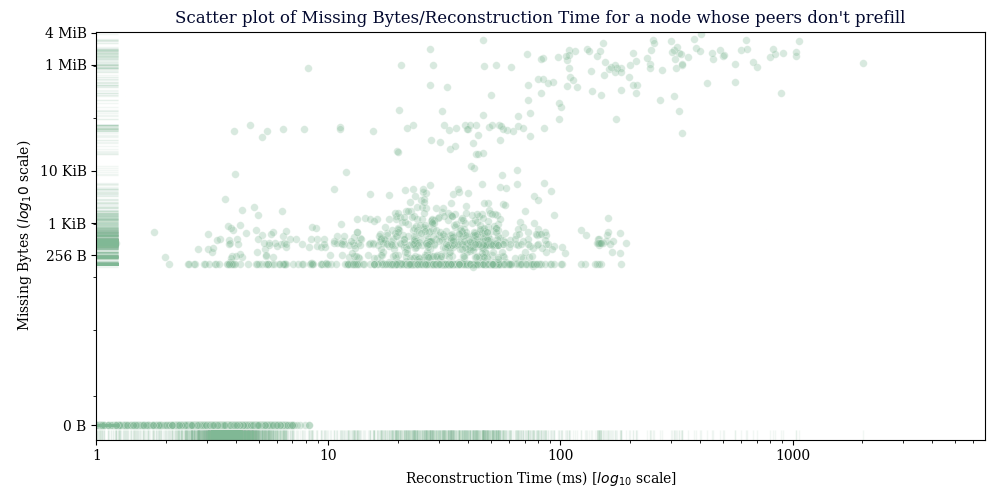
This data was gathered from a node configured so that it would only receive CMPCTBLOCK announcements from our prefilling node, the main thing to see here is that reconstruction generally succeeds, the average reconstruction time metric is misleading, since we don’t count extra RTT’s that happen in the TCP layer in reconstruction time, just the time we receive the CMPCTBLOCK until the time we have reconstructed it.
49 out of 2793 blocks received failed reconstruction. (1.75%)
Reconstruction rate was 98.25%
Avg size of received block: 55851.93 bytes
Avg bytes missing from received blocks: 603.40 bytes
Avg bytes missing from blocks that failed reconstruction: 34393.55 bytes
Avg reconstruction time: 7.821697ms
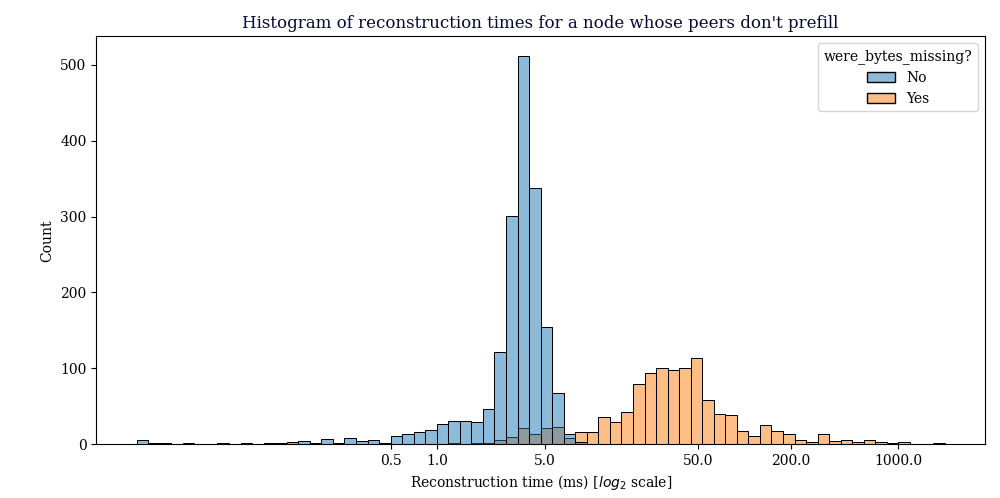
Prefilling Node: stats on CMPCTBLOCK’s received
This data was gathered from the node that sends prefilled compact blocks to its peers. Because this node is otherwise unmodified, we can use its measurements on the receiving side as a baseline for block reconstruction on nodes today.
1101 out of 2883 blocks received failed reconstruction. (38.19%)
Reconstruction rate was 61.81%
Avg size of received block: 15957.20 bytes
Avg bytes missing from received blocks: 47849.36 bytes
Avg bytes missing from blocks that failed reconstruction: 125294.91 bytes
Avg reconstruction time: 25.741588ms
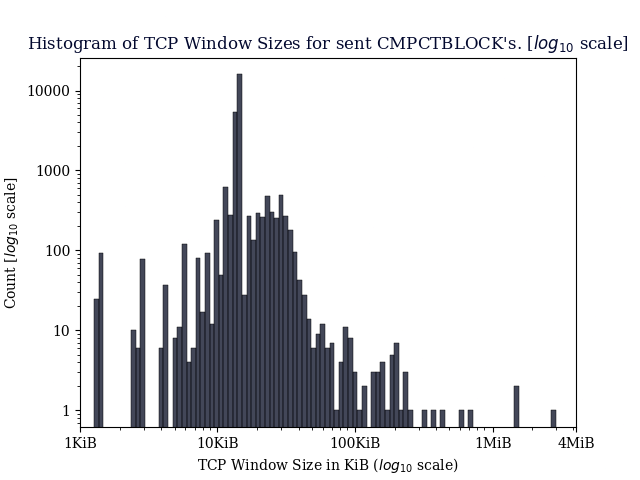
TCP Window data
There is a flaw in the window available bytes metric I have used, pointed out to me by @hodlinator, which is that I only did window_size - cmpctblock_size, and did not factor existing bytes queued to send to peers in vSendMsg. I anticipate this will have a small effect, but a branch which prefills up to the TCP window limit should take this into account.
Edit:
@andrewtoth has pointed out more complications in the available bytes metric: it will also have to take into account the current in-flight segments to the peer. On Linux, for example, this is tcpi_unacked (Multiplied by tcpi_snd_mss to get size in bytes). It will also have to account for bytes that are in the operating system’s send queue (tcpi_notsent_bytes). But I believe that because Bitcoin Core uses TCP_NODELAY the OS send buffer should generally be empty. On Linux, the sum of these two values can be obtained with SIOCOUTQ:
int bytes_inflight_and_unsent, err;
err = ioctl(socket, SIOCOUTQ, &bytes_inflight_and_unsent)
I found this article helpful: Journey of Life: TCP socket send buffer deep dive (archive link)
TCP Window Size: Avg: 16128.76 bytes, Median: 14480.0, Mode: 14480
The mode represented 13076/26392 windows. (49.55%)
Avg. TCP window bytes used: 7449.62 bytes
Avg. TCP window bytes available: 8679.14 bytes
Prefilling node: stats on CMPCTBLOCK’s sent
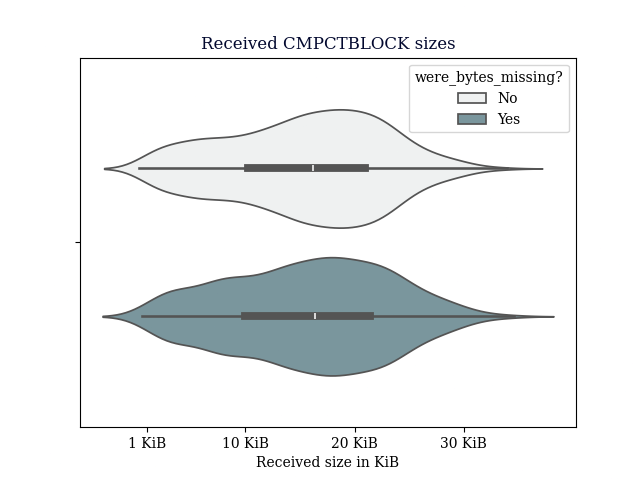
The average CMPCTBLOCK we sent was 65732.80 bytes.
The average prefilled CMPCTBLOCK we sent was 91614.48 bytes.
The average not-prefilled CMPCTBLOCK we sent was 14483.78 bytes.
17536/26392 blocks were sent with prefills. (66.44%)
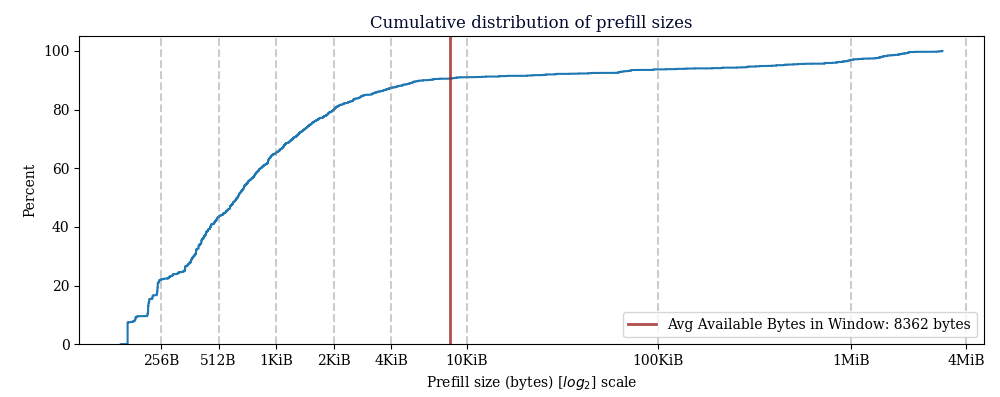
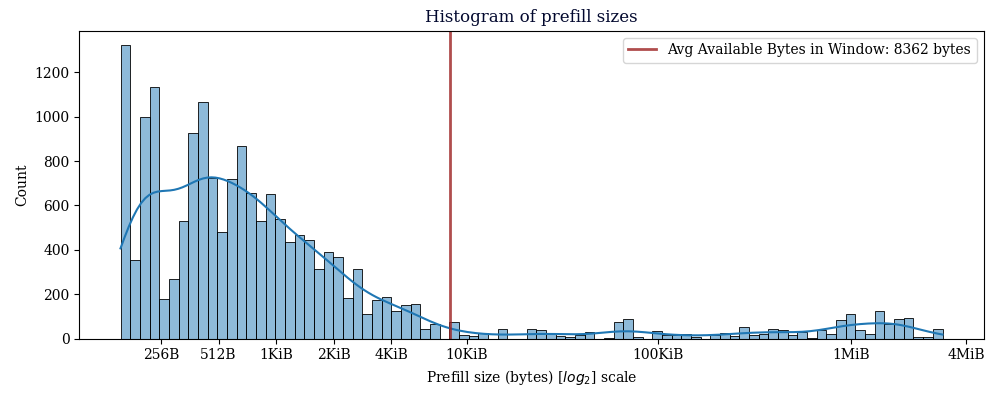
Avg available prefill bytes for all CMPCTBLOCK's we sent: 8679.14 bytes
Avg available prefill bytes for prefilled CMPCTBLOCK's we sent: 8362.04 bytes
Avg total prefill size for CMPCTBLOCK's we prefilled: 74593.04 bytes
15042/17536 prefilled blocks sent fit in the available bytes. (85.78%)
The average prefill size is notably large, but this is a consequence of some outlier blocks.
vExtraTxnForCompact
But, we can probably do even better, since the above statistics are for prefilling with all of the transactions in vExtraTxnForCompactBlock, and as I understand, it is very likely for peers running the same branch of Bitcoin Core to have a similar vExtraTxnForCompactBlock’s to one another. So it is likely that reconstruction will often succeed even without these transactions, so they should be the first candidates for not being included in the prefill. Unfortunately, their size is not something that Bitcoin Core logs, although I tried to compute it with a heuristic: prefill_size - missing_txns_we_requested_size, but it turned out this was very incorrect.
Overflowing window before pre-fill.
Interestingly, some compact blocks were already so large before prefilling that they required more than one TCP round-trip to be sent, while this circumstance is not ideal, prefilling performs better by taking advantage of this.
1432/26392 CMPCTBLOCK's sent were already over the window for a single RTT before prefilling. (5.43%)
Avg. available bytes for prefill in blocks that were already over a single RTT: 8555.57 bytes
1432/1432 excessively large blocks had prefills that fit. (100.00%)