After @instagibbs reported success in using Claude for rebasing ln-symmetry, I had a go at messing with it too. While it seems very useful in general, I think one place that’s worth talking about is using it as a review aid: PR review has long been recognised (eg) as a bottleneck in Bitcoin Core at least, and AI’s certainly lowering the barrier to creating new PRs which won’t make things easier.
I think there’s a few different goals when reviewing a PR that are worth being a bit explicit about:
- does this actually do what it’s supposed to?
- is doing this a good thing? if it is a good thing, is it worth the cost? are there more important things that should take priority?
- could this be done better?
- are the changes properly tested?
- do I understand the change well enough to fix any bugs in it that get found later?
With this in mind, I found two pretty strong biases that I didn’t think were very helpful:
- Claude would largely take it for granted that the idea was good and worthwhile, and only review correctness.
- Claude would largely try to do everything itself – form an opinion and state a conclusion and even offer to post that as a PR review, sometimes even before I’d had a chance to look at the commits myself.
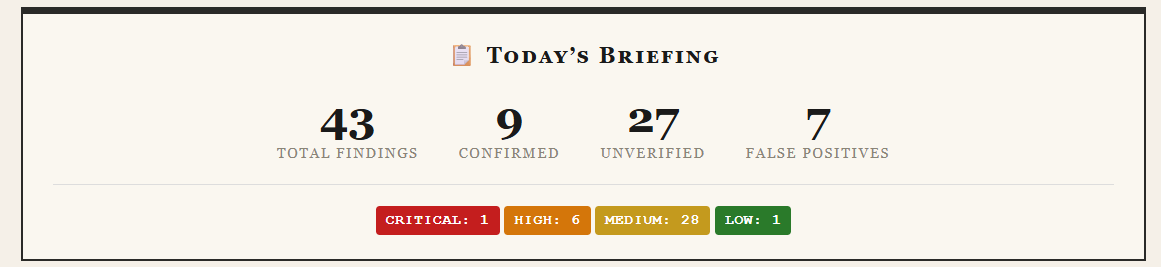
I think the “is it worthwhile” one is probably just hard; it’s not that easy for humans either really. My test case for that was PR#34444, and as per the comment, even if its review contribution wasn’t helpful, it was still helpful for me overall.
But the “I’ll just do everything for you” aspect doesn’t seem so helpful – if you want to improve review, you want to add “brainpower” to the review process, not subtract it. So the approaches I’ve looked at for this is a few things:
- telling it to run a sub-agent and do a review, but keep the results of the review private until I’ve done my own review, so that we can then compare them (it immediately summarised the results when the agent finished, of course)
- telling it that I’m stepping through each commit, and to quiz me on anything that seems complicated in the commit (this worked pretty well, and found a couple of things I didn’t understand fully) Helps to disable “show tips” via /config, or else the quiz answers will appear as suggested responses, though…
- asking it for help doing things when I’m stepping through – in particular, I’ve always found it hard to get code coverage reports and iwyu/clang-format results; telling the AI to do that for me has been great
I’m not sure how much it helped, but telling it various resources about the PR and getting it to do a sub-agent that summarises those as a resource to use before beginning the rule might be a good idea.
Using it as a project manager (“oh, I should do X, remind me about that when I’m done with Y”) was also very helpful. I’ve gone so far as to feed it my various blog posts on Bitcoin so it can help prioritise tasks at a higher level too, and so far it seems like that works okay too.
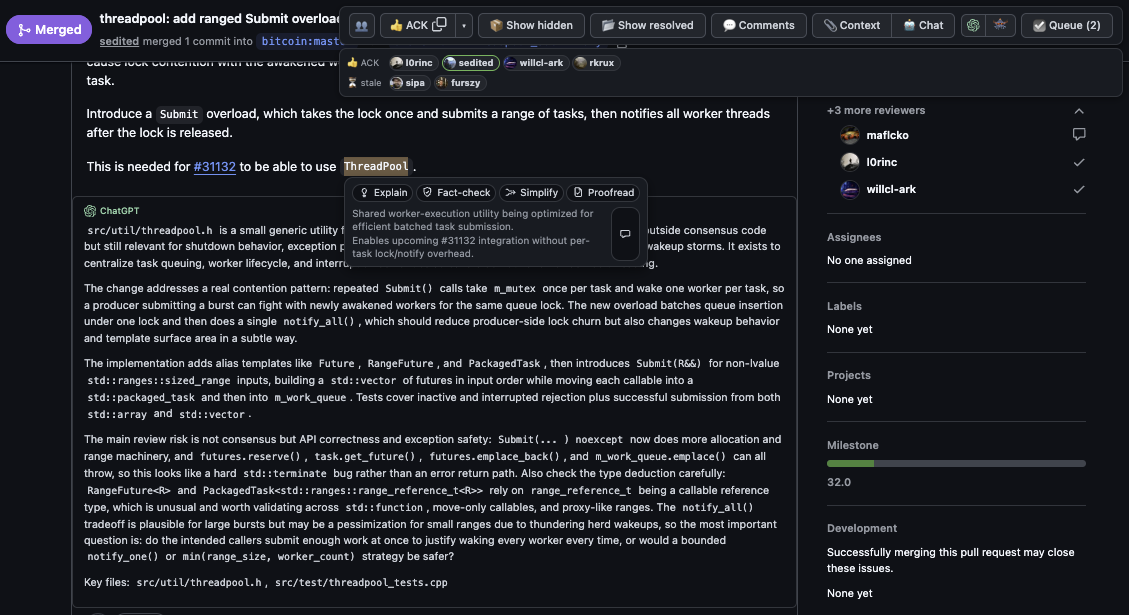
Anyway, I used that approach very heavily in my review of PR#34257 and PR#34023 for cluster mempool related improvements, and found it pretty effective. The AI’s initial self-review almost immediately spotted an inverted condition in a test, and then having the AI assist with code-coverage reporting on the fuzz corpus helped validate that it really was behaving as it seemed. For the SFL optimisation stuff, I tried getting it to have a sub-agent review the code prior to the PR and suggest its own optimisations and then see if those matched the PR, or if anything was missing. It did claim to pick out the most valuable change, while missing most of the minor ones, but that didn’t really add anything to the review.
Probably the key bits of my overall prompting stuff are these bits (mostly copied from a tweet I saw or self-generated by claude):
## Core Principles
### Simplicity First
- Make every change as simple as possible. Impact minimal code.
- Find root causes. No temporary fixes. Senior developer standards.
- Changes should only touch what's necessary. Avoid introducing bugs.
### Plan Before Executing
- Enter plan mode for ANY non-trivial task (3+ files or architectural decisions)
- If something seems off, STOP and re-plan immediately - don't keep pushing
- Write detailed specs upfront to reduce ambiguity
### Verification Before Done
- Never mark a task complete without proving it works
- Run tests, check logs, demonstrate correctness
- Ask yourself: "Would a staff engineer approve this?"
### Self-Improvement Loop
- After ANY correction or finding: update `lessons.md` with the pattern
- Write rules that prevent the same mistake
- Review lessons at session start
### Autonomous Investigation
- When given a potential bug: just investigate it, don't ask for hand-holding
- Point at logs, errors, failing tests - then resolve them
- Zero context switching required from the user
### Interactive Assistance
- Claude assists; the user drives. Don't produce finished artifacts and
offer to post them. Present work incrementally and wait for direction.
- When in doubt about the next step, ask rather than assume.
### Demand Elegance (Balanced)
- For non-trivial changes: pause and ask "is there a more elegant way?"
- Skip this for simple, obvious fixes - don't over-engineer
Now that I actually look at that, I guess the “Autonomous Investigation” and “Interactive Assistance” sections are in some conflict there. Oh well!
It’s not currently clear to me what resources from a session would be interesting to publish – so far I haven’t personally looked much at either the docs or the project files that it generates; I’m more just using them as the AI’s long-term memory so we can both pick back up where we left off. For conversations with ChatGPT and the like, just posting a log of the conversation can make sense, I think (eg), but it’s not clear to me what would be similar for an agent-based project.
(For those interested I’m running it in a dedicated VM, with a read-only github token for looking up PRs, and no push access/etc. I haven’t tried running with local models, or Codex or OpenClaw etc)
Anyway, thought I’d share. Anyone else trying something similar?