Motivation and Background
Currently, when miners want to determine whether a block template with more fees is available, they repeatedly poll the getblocktemplate RPC until a better template is returned (relative to the one they are working on). This approach can lead to redundant block template builds in some cases.
The experimental mining interface introduced in Bitcoin Core v30, waitnext(), improves this by allowing clients to wait and receive a new block template after a noticeable fee increase or when the blockchain tip changes.
However, internally, waitnext() also regenerates block templates every second.
Building a block template locks Bitcoin Core mutexes, (mempool (cs) and cs_main) throughout the build. These locks prevent concurrent access during template generation for thread safety purpose, which can delay transaction processing and relay to peers.
A better approach is to track the potential fee increase resulting from each mempool update that affects the current block template. The node can then decide whether rebuilding the template is worthwhile based on the accumulated fee increase.
Implementing this in current Bitcoin Core is challenging because, for each mempool update, the effective chunk fee rate of affected transactions is not explicitly known [0].
However, with the introduction of the Cluster Mempool [1], this limitation no longer applies.
This post explores a simple method that leverages Cluster Mempool feature to determine whether there has been a potential fee rate improvement in a block template without requiring a full rebuild.
Prerequisites
Definitions
- Fee Rate: The fee of a transaction divided by its size.
- Chunk: A grouped list of related transactions that should be mined together.
- Chunk Fee Rate: The total fees of all transactions in a chunk divided by their total size.
- Fee Rate Diagram: A monotonically decreasing list of chunks used to plot a graph where the y-axis represents the fee and the x-axis represents transaction size.
Block Template Fee Increase
The objective is to determine the potential fee increase of a block template as the mempool evolves, without rebuilding the block template using the node’s block assembler.
Given a previously built block template, compute/save:
Mempool Update Scenarios
When a new transaction enters the mempool, two primary cases occur:
-
Addition without in-mempool conflicts The transaction connects to zero or more existing clusters. A new linearization is computed for the affected clusters, producing both an old and new fee rate diagram.
-
Addition with in-mempool conflicts The transaction conflicts with one or more existing transactions in the mempool. The connected clusters are re-linearized, generating both old and new fee rate diagrams.
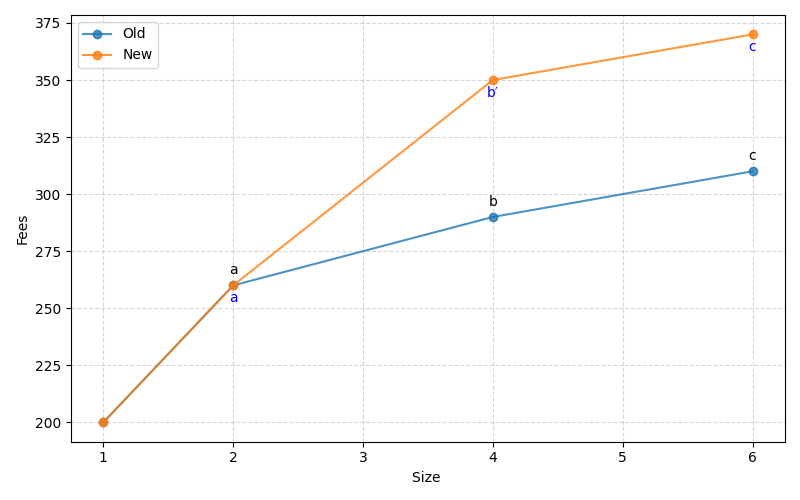
Naive example of mempool addition of b′ that improves the fee rate of b.
In both cases, the addition is accepted iff the new fee rate diagram is strictly better.
There is also a rare case where update has only the old diagram, for example, when the mempool is full and the lowest-fee chunk is evicted. This is uncommon, as miners typically run nodes with large mempools, but it should still be handled.
After an Update
If there is an old diagram:
Initialize an empty temporary list \text{New}_R = \{\}.
For each chunk c in the old fee rate diagram, if r_c \ge r_L, add c to \text{New}_R.
Maintain \text{New}_R in ascending order by fee rate.
Iterate through \text{New}_R:
For each chunk c \in \text{New}_R (from lowest fee rate):
$ \begin{cases} \text{if } c = L: & \text{Remove } L \text{ from block template} \ & \text{Update } L \text{ to the new worst chunk in the remaining block template} \ & \text{Remove } c \text{ from } \text{New}R \ & F{\text{modified}} \leftarrow F_{\text{modified}} - f_c \ & S_{\text{modified}} \leftarrow S_{\text{modified}} - s_c \ \text{else if } r_c > r_L: & \text{Exit loop — all remaining chunks have } r_c > r_L \end{cases} $
After the loop, add all remaining chunks in \text{New}_R to the persistent set R (chunks with r_c > r_L that were removed but not equal to the old L).
If there is a new diagram:
For each chunk c in the new fee rate diagram, if r_c > r_L, add c to A (maintained in descending fee rate order).
Evaluating Potential Fee Increase
Phase 1: Remove evicted chunks from block template
Loop through the block template chunks. For each chunk c:
- If any chunk in R matches c, remove it from the block template. Subtract its fees from F_{\text{modified}} and its size from S_{\text{modified}}.
Clear R afterward.
Phase 2: Perform naive merge
Initialize:
Iterate through chunks in A (in descending fee rate order):
If S_{\text{naive}} + s_{a_i} \le W, then:
Compute:
- If \Delta F \ge F_{\text{threshold}}: rebuild the block template.
- If all chunks in A are added and \Delta F < F_{\text{threshold}}: stop (insufficient improvement).
Phase 3: Iterative merge (if naive merge is inconclusive)
If the naive merge shows potential but is inconclusive, perform an iterative merge of the block template chunks and chunks in A:
-
Initialize an empty block template and fill it by selecting the best chunks from both the existing template and A.
-
Stop when:
- Block weight W is reached,
- No chunk from the template or A will fit, or
- The iteration limit is reached.
Compute:
- If \Delta F_{\text{new}} \ge F_{\text{threshold}}: build and return the new block template.
Phase 4: Update state
After building a new block template:
- Clear A
- Set the new template as the current one
- Update L to the worst chunk in the new template
- Update F_{\text{modified}} = F_{\text{new}}, S_{\text{modified}} = S_{\text{new}}
Implementation Note
This computation can be handled asynchronously by a Block Template Manager (as proposed in Bitcoin Core Issue #33389).
It should operate independently of cs_main and mempool locks by using a validation interface notification executed in a scheduler thread after each mempool update.
This notification provides both old and new fee rate diagrams, which is also useful for the block policy estimator [2].
The Block Template Manager maintains its own internal locks to ensure thread safety without blocking mempool or transaction relay operations.
Limitation
This approach does not account for bin-packing effects at the block template tail [3].
References
[0] Proposal for a new mempool design
[1] Cluster Mempool
[2] Package-Aware Fee Estimator Post Cluster Mempool
Original post https://delvingbitcoin.org/t/determining-block-template-fee-increase-using-fee-rate-diagram/2051 deleted mistakenly sorry for the noise