Introduction
To route a payment on the Lightning Network, a sender must choose a path to the destination using channels which contain sufficient liquidity and meet certain forwarding rules (e.g routing fees). As neither the liquidity nor the balance in payment channels are shared with the network, a sender does not know if there is sufficient liquidity in each channel when constructing a path. This is referred to as liquidity uncertainty. With no other mechanism to resolve this uncertainty, nodes are left to a trial-and-error strategy. That is, attempt the payment anyway and hope it works. If it doesn’t, update the local view of the graph and try again. This approach to routing has a host of issues:
1. Sub-optimal routing
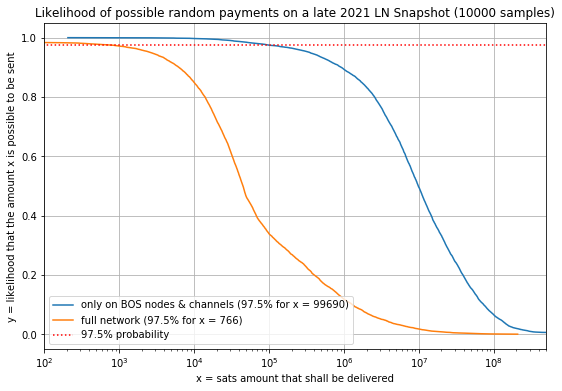
Without prior knowledge, a channels probability of error due to insufficient liquidity approximates the ratio of the payment amount to the channel capacity, which means larger payments through relatively low capacity channels are prone to error. Furthermore, this risk is compounded at every channel, which means longer paths become exponentially difficult. See appendix A for details.
Routing calculations must account for this uncertainty by favoring shorter paths and higher capacity channels. Not only does this effect the payment sender who’s more likely to pay extra in fees for reliable liquidity, it’s also a centralizing force on the network. See appendix B for details
Low payment success rates implies a large set of potential routes. When the final route is unknown, routing fees are more difficult to predict.
Failed payments are a burden to routing nodes in the failing sub-path in the form of locked liquidity, HTLC slots, and wasted computational resources.
2. Slow Discovery Process
By using payments to discover feasible paths, HTLCs need to be set up and torn down at each hop, which requires multiple rounds of communication between peers. This is a lot of wasted time whenever a payment fails. Furthermore, this process must be executed serially to avoid the delivery of multiple successful payments, which fundamentally limits the rate at which path discovery can occur.
3. Routing limitations
To route a payment, the sender needs the latest updates to the graph. This requirement is a burden to the sender, who needs to constantly sync the channel graph, and to routers, who must limit their channel updates.
Proposal
Allow nodes to share routing information with each other in the form of path queries. The proposal includes the following optional messages, which allow nodes to cooperatively construct a path:
path_query
-
source_node_id
-
destination_node_id
-
amount
-
expiry
path_reply
-
path
-
amount
-
fees
-
cltv_delta
-
reject_path_query
- reason
Upon receiving a path_query, a node can choose how it wants to respond, including rejecting or ignoring it. The path_reply message helps the requester deliver a potential payment because it leverages routing information at the queried node. Notably, this solves the liquidity uncertainty problem for the queried node’s channels because a node knows it’s own balances and can respond accordingly. In contrast to the single execution onion, queries are lightweight and can be made concurrently. A parallel discovery process reduces liquidity uncertainty at a significantly faster rate than onions. Finally, it’s worth noting that a router can respond with any policy (e.g fees) it desires, unconstrained by existing rate limits.
Putting into practice
The proposal outlines a basic set of messages and it is for the node to choose their own request & response strategies, including who they want to talk to (any subset of nodes), what they want to respond to (e.g minimum amounts) and any rate limits (number of requests and replies/paths). While there are innumerable strategies that may evolve, let’s walk-through a simple example where all nodes adopt a PEER_ONLY strategy (i.e nodes interact only with their channel peers):
+--- A ------- B ---+
| | |
| | |
L ----- S +---------+ R
| | |
| | |
+--- C ------- D ---+
Before attempting the payment, the sender (S) may choose to query any subset of it’s channel peers. The sender already knows that (L) is a leaf so does not query it. Alice (A) advertises the lowest routing fees but, since this is a larger payment, the sender decides to make concurrent queries to both Alice and Carol:
- Alice receives a
path_querymessage requesting a path from herself (A) to the receiver (R). She sees she does not have the outbound liquidity to Bob (B) to complete the payment, so can either immediately respond with areject_path_querywith a reason indicating a temporary failure to find a route, or wait until liquidity becomes available to send apath_reply. - Carol (C) receives a
path_queryrequesting a path from herself to the receiver (R). She has sufficient outbound liquidity through Dave (D), but before responding to the sender, she decides to query Dave:- Dave receives a query from Carol for a path from himself (D) to the receiver. Similar to Alice, Dave responds that he has no route available
- Upon discovering insufficient liquidity from D → R, Carol splits the sender amount and concurrently queries Bob (B) and Dave (D) with their respective splits.
- Dave receives a new query requesting a path from himself (D) to the receiver, but of a lesser amount. This he does have the liquidity for! Since Dave knows he can route the requested payment, he responds to Carol with the given path and routing details.
- Bob (B) receives a new query requesting a path from himself (B) to the receiver for his split amount. Similar to Dave, he knows he can route the payment, so resonds to Carol with his routing details.
- Upon receiving the path details from Bob and Dave, Carol can now confidently assemble a MPP from herself to the receiver. She constructs the MPP, adds her own routing details and sends a
path_replyto the sender. - Upon receiving the
path_replyfrom Carol, Alice attempts the payment and on her first attempt, the payment succeeds.
As you can see, path queries enable nodes to use queries to concurrently probe the network for feasible paths. When chained together, these queries swarm to the destination. Each hop knows it’s channel balance and can therefore reduce the liquidity uncertainty for their channel(s) in the path. After receiving a path_reply a node can prepend itself to the path and back-propogate it to the source.
While the small example above illustrates the process, it is important to remember that liquidity uncertainty is particularly detrimental for longer paths on larger networks; trial-and-error may work for a small network like this, but does not scale to a growing number of nodes.
Benefits
As a simple set of flexible messages, it’s impossible to define all potential use cases. However, benefits can be broadly outlined as follows:
- Improves routes for larger payments, including lower fees, lower expected payment delivery times, and better fee estimation.
- Eliminates reliance of a fully synced channel graph. This is especially useful for mobile nodes who are not always available to receive updates and may prefer a relationship with an LSP.
- Enables more dynamic routing policy, whereby nodes can share updates without globally enforced rate limits.
- Distributes routing more evenly across the network, making smaller routing nodes more competitive
- Allow for network growth
Addressing potential concerns
- Privacy.
Naturally, any time information is shared, there is a privacy implication. However, this proposal is entirely optional; a node may choose to reveal as much or as little information to whomever they choose. For example, rather than revealing the true payment destination, a node can query a sub-path, which nicely compliments blinded paths.
Additionally, the use of onion messages could significantly improve a node’s anonymity set, especially when querying node’s multiple hops away.
- Denial-of-service
Nodes may choose their own response strategies, including filtering requests (e.g minimum amount) and setting rate limits.
Expanding the messages
The messages defined in this proposal are pretty bare. New fields can be added to these messages to enhance a node’s capabilites:
- Filters to the
path_queryto reduce the number of reply messages, such as amaximum_fee - Confidence scores that tell the requester the expected likelihood of payment delivery; the higher the routing node’s confidence, the more a path suggestion behaves like a quote for delivery.
- Time limits. A node can define a window of time their interested in a given path (e.g 1min, 1hr, 1day, always) and get notified with updates.
Comparisons to Trampoline
As far as I can tell, path queries can be used to accomplish everything trampoline routing proposes. The trampoline proposal states, “The main goal of trampoline routing is to reduce the amount of gossip that constrained nodes need to sync”. Furthermore, it states “constrained devices should only keep a small part of the network and leverage trampoline nodes to route payments.” With path queries, a node does not need any knowledge of the graph, but instead only a connection to a supporting peer.
Trampoline pursues this goal while also preserving anonymity for the sender and receiver. This is done by including multiple hops in the trampoline route. Using path queries in the form of onion messages, a source node can attain a comparable anonymity set with only a single ‘trampoline hop’ using the following process:
- Select a node with path query support as a ‘trampoline’ hop.
- Query channel peer for a path to trampoline.
- Query trampoline for a path from trampoline to final destination.
- Send payment using aggregate route
Note that while the pathfinding process is similar to trampoline in that it leverages routing information of other nodes, the final route does not use a special “trampoline route”, but rather a regular onion route. This means the trampoline hop has no information about the source other than the in-bound channel.
Also, by requiring only a single trampoline hop, the full route is likely to be shorter. And as discussed above, paths derived from queries are likely to have higher success rates and lower fees while moving across the network.
Moving Forward
My primary goal is to get feedback, iterate on the proposal and open a draft PR into the BOLTs. Moving forward, I would be happy to work with any implementations interested in this feature.
Appendix A - Payment Failure Probabilities
Referencing Mastering the Lightning Network
For a given channel
The success probability function (only considering liquidity) is:
P(a) = (c + 1 - a)/(c + 1), where a = payment amount, c = channel capacity
Using limits for approximation, we can eliminate the +1s and reduce the function to:
P(a) = (c - a)/c = 1 - (a / c)
As an additive inverse, we can deduce our probability of failure due to liquidity as (a / c) - the ratio of payment amount to the channel capacity.
For a payment path
The success probability of a payment path is the product of probabilities for each channel in the path(s):
Likewise, probability of failure is a product of probabilities.
Appendix B - Network Centralization
As this 2021 study shows, channel attachment strategies that connect to central nodes (e.g High degree, Betweeness) have significantally better payment success rates and better overall performance than more distributed strategies (e.g k-median), even when the distributed strategies offer lower fees. This is evidence that short paths through high capacity channels give larger routing nodes (high channel count, high capacity) a competitive advantage for larger payments, allowing them to capture more in routing fees.
Additionally, payment success probabilities are higher for nodes with more volume (see here) because their previous payment attempts reduce their liquidity uncertainty. Lower uncertainty ultimately leads to better payment performance, meaning small nodes are at a disadvantage as a payment originator as well as routing.