(Also posted on twitter: https://x.com/cguida6/status/1968117953871720463)
(Also posted on nostr: (Also posted on twitter: ) Several core supporters have pointed me to Pieter ... )
Several core supporters have pointed me to Pieter Wuille’s recent StackExchange post[0] explaining core’s rationale for raising the default opreturn limit 1250x from 80 bytes to 100,000 bytes in the upcoming bitcoin core v30. I don’t know where else to publish this response, because I don’t know what apps Pieter uses, and StackExchange does not seem like the right place for a constructive back-and-forth.
(Edit for Delving: Thanks to @moonsettler for reminding me that @sipa uses Delving. I think Delving is probably the right place for this discussion to take place, if indeed it is a discussion and not just a single one-way post with no followups, as I have experienced in the past on here. I did not post this response to StackExchange as it is designed for exactly the kind of 1-question-1-answer dynamic I am trying to avoid).
My goal here is to challenge Pieter’s explanations with claims and questions of my own, in order to:
- find any pieces of Pieter’s rationale that I am misunderstanding or lacking,
- inform the public as to what I believe to be the most compelling arguments against removing the opreturn limit, and
- ultimately, to arrive at the real truth of the matter and help bitcoin follow an optimal path
So I’ve taken Pieter’s post and responded inline here (paragraphs with double arrows are the original SE question asker, those with single arrows are Pieter, and those without arrows are me):
Given the debate around the issue I think this is probably an opinion-based question, but I’d still like to try to clear up some misconceptions. Disclaimer: I’m a Bitcoin Core contributor, argued in favor of dropping the OP_RETURN restriction, and co-authored a document on the matter that was signed by several other contributors and got published on the http://bitcoincore.org website (which I recommend you read). While I’m only going to give my own view below, I think I have a good idea on at least the proponents’ opinion on the matter.
Yep, you definitely seem to be the most authoritative voice on the “pro-32406” side of the debate. You are also obviously one of the most important devs in bitcoin history, and your claim to being “a Bitcoin Core contributor” is a massive understatement.
I agree that Bitcoin is money, not a storing database, and strictly only monetary data should be on the blockchain.
I agree with this, and have argued strongly in the past against developing solutions that relied on using the chain purely as a publishing mechanism for non-financial data. Blockchain space can be expensive, slow, unreliable, and costly (in terms of bandwidth/processing by nodes). It should be used for what it’s good for: proving that censorship-resistant payments are valid to the world; a use case for which no better alternative exists, as opposed to many data-publishing use cases that have no such requirements.
Yes, I’m glad that we agree on this.
I believe that in the long term, such (in my view) sub-optimal use will be driven to alternative solutions anyway as on-chain space grows more valuable, and that deviations to this, like we see now, are temporary convenience solutions driven by hype.
I think this is where we disagree. Greg Maxwell argued[1] in 2015 that “Demand for cheap highly-replicated perpetual storage is unbounded”. I agree with Greg. If we do not impose any additional costs on people trying to use bitcoin as a general-purpose database, such use will *absolutely* drown out payment use cases, especially merchant Lightning nodes which, at the moment, are bitcoin’s most important payment use case.
I think filters make it *look like* there is no demand for large opreturns, just as the fence around your house makes it *look like* there is no demand for trespassing on your property. Deterrents are often misunderstood, because you can’t see all the attempts that never happened, *precisely because of the deterrent*.
It’s worth warning people that they likely won’t persist with changing economics, and provide some discouragement for it - but not when that discouragement becomes harmful on itself (see further).
I’m not sure what you mean here by “they likely won’t persist with changing economics”… if your assertion is that altcoin Ponzis will magically stop happening *just* because of on-chain fees… I don’t think that’s likely true at all; one look at the “crypto industry” outside bitcoin should be sufficient to explain why. But maybe that’s not what you were saying?
However, as developers and community of node runners, we also do not really get to decide what people use the chain for, beyond agreeing on consensus rules(*).
This is another point of disagreement. The noderunners *absolutely must* enforce bitcoin’s usage as a payment network and reject attempts to use bitcoin as data storage since, as I already mentioned, demand for perpetual, highly-replicated storage is infinite, and therefore there is no way the consensus rules *themselves* can prevent data use cases from drowning out payment use cases. Even with a fork to disallow almost all script types, there would still be people making crazy schemes on top of fake pubkeys or whatever in order to facilitate their token Ponzis. Ponzi participants are not particularly sensitive to fees, if the promise of getting rich quick is compelling enough.
Put more simply: bitcoin’s identity as money cannot be enforced at the consensus layer. Therefore, the only way to ensure that bitcoin stays money is if we enforce its usage as money at the social/mempool layer. The only reason bitcoin has stayed money thus far is because of its protective “bitcoin maximalist” culture, which ensures that its #1 priority is always to be the best money, and that other use cases are severely discouraged.
In the absence of strong mempool filtering (and possibly other social-layer mechanisms), I don’t see a way for data use cases *not* to gain such a dominant role that bitcoin ceases to be money entirely. It just seems inevitable to me.
The reason filters are effective at deterring unwanted data use cases is that the filter serves as a warning that is backed up by the noderunner community’s will. The warning says: “we don’t like transactions that store more than 80 bytes of arbitrary data, so if users attempt to work around this, we will take action to mitigate such usage. If our mitigations don’t work, we will continue escalating until the spammers leave.” This is exactly what we did in 2014[2], and is exactly what will work today.
The contents of blocks is decided by miners, who are - by design - driven by economic incentives.
If you are implying that fees are the only “economic incentives” miners pay attention to, this can be easily disproven by considering the result of the block size war; larger blocks promised *much* larger fee revenues for miners than small blocks (and presumably number-go-up in the short-term because of perceived “scaling”), and yet the small blockers were victorious. Miners were forced to concede that a bitcoin with smaller blocks and segwit would be much more economically valuable in the free market than a bitcoin with large blocks and no Lightning Network.
(Similarly, a bitcoin that is easy for merchants to accept directly because their Lightning channel opens and closes aren’t being overrun by altcoin speculative manias is much more valuable in the free market than a bitcoin that is filled with spam.)
That is: miners must also pay attention to long-term incentives in addition to short-term incentives. Sometimes it takes some nudging from the user community in order to help them decide, but eventually the market will always converge on whichever version of bitcoin is the most valuable, and miners must pay close attention in order to make the right choice.
And if people are willing to - hopefully temporarily - pay more for “dumb” data storage on chain than real payment activity, there is little that can be done about this, for a multitude of reasons:
Data can always be disguised as payments,
Yes, this is precisely why the consensus rules are useless for making sure bitcoin stays money, and why we must react at the policy level rather than the consensus level. Only the most popular formats, which by definition are easily-identifiable, need to be filtered.
making attempts to stop or even discourage it a cat-and-mouse game, which at best pushes those who pay for these use cases to slightly less efficient techniques (like encoding the data in addresses, amounts, signatures, …).
No, at best the spammers *leave bitcoin entirely* and go to other chains, as they did in 2014 (again, see [2]). We won the cat-and-mouse game last time; why assume we would lose this time? This assertion has no evidence.
Given enough economic demand for data storage, nothing prevents submitting transactions directly to willing miners (which fundamentally can’t be prevented(*)), bypassing non-mining nodes, the software they choose to run, and thus ultimately, their influence entirely.
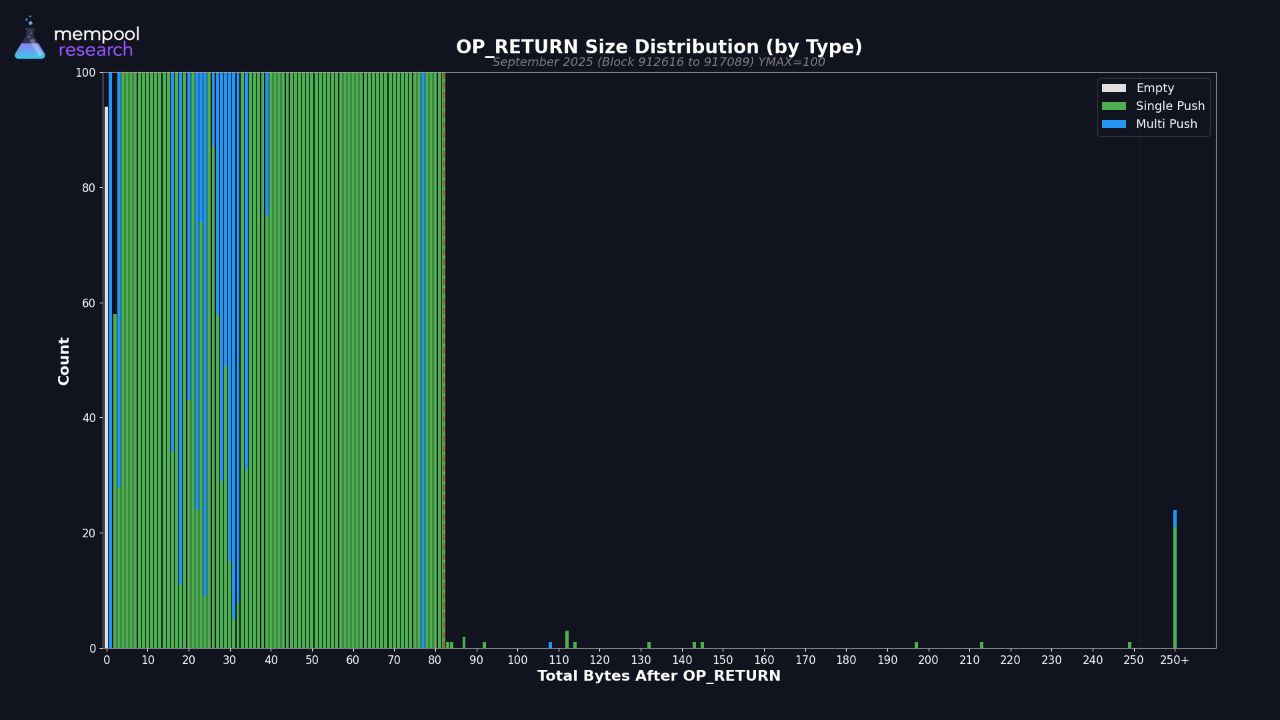
Of course, but the goal of spam filtration is not *the complete elimination of spam*; the goal of spam filtration is just to make the system usable for its intended purpose. On bitcoin, this means making sure bitcoin stays money by making sure that the majority of activity on the network is payments, not data. The opreturn filter is performing this role admirably, as can be seen by the 99% reduction in large opreturns[3][4] it causes.
Philosophically, would you want a Bitcoin in which some (significant, but far from universal) subset of node runners get to decide which transactions are allowed or not, given that that, if effective, the same mechanism could be used to block “undesirable” payments, while providing a censorship-resistant payment system was the very thing Bitcoin was designed to enable?
This argument doesn’t make sense to me. You just argued that users can always submit transactions directly to a miner. So bitcoin is still censorship resistant, even if the relay network is entirely hostile nodes, entirely blocksonly nodes, or even if the relay network doesn’t exist at all. So I don’t see how a supermajority of noderunners running filters does anything to change bitcoin’s censorship resistance. Bitcoin is censorship resistant, period. So spam filtration is an entirely different matter from censorship.
Second, if a supermajority of noderunners is running a filter, *this is the only mechanism by which the user community can enforce bitcoin’s moneyness* since, as previously pointed out, bitcoin’s moneyness cannot be enforced at the consensus level. Thus, if a filter is being run by a supermajority of nodes (assuming no long-term sybil attacks), this must be considered the bitcoin network’s will, and going around it should be considered abusive. I very much doubt that a supermajority of noderunners could be convinced to filter OFAC transactions, for example. But again, if that does somehow happen, there’s always direct-to-miner submission APIs (and other more decentralized solutions such as gudnuf’s hackathon project, memcooler[5]).
Of course, ultimately the agreement of all Bitcoin users (the consensus rules, see below(*)) determines what transactions are allowed, but this being hard to change is a feature, not a bug.
Again, if we require consensus changes in order to prevent spam, we will obviously lose to the spammers. There is no way consensus rules can keep up with rapidly evolving threats from Ponzi scammers. But modular filters[6] can easily keep up with such threats.
I still find it hard to understand the argument on favor to this change. As far as I understand the OP_RETURN will be relaxed from 80 Bytes to 100k bytes, allowing the storage of arbitrary data, like images and even small videos. Why ? I hear often “Arbitrary data is already been placed on the blockchain”, but then why the complacent attitude towards it ? and not fight the spam instead ?
To be clear, Bitcoin Core v30 lets node runners configure the OP_RETURN size limit (the -datacarriersize config option). The only change is that its default value is increased (to effectively unlimited).
The change of the default is the important feature of this discussion. The fact that the control was left in is not significant in comparison. Up until recently, core had >95% share of the nodes, and this is more than sufficient for the default to be very sticky. Nodes that dissent from the default don’t have much effect on the actual incidence of transactions that get confirmed.
It is marked deprecated, which means the option is expected to be removed in a future version, but given the current political dispute around it, I do not expect that will happen any time soon.
It is remarkable that it was even considered to remove the filter entirely. This would have meant that any miner wanting to filter large opreturns would need to either stay on core v29 forever or switch to knots. As it is, any miner wanting to disallow transactions with *multiple* opreturn outputs will have only these options once v30 is released. As is, the change is remarkably heavy-handed, but it would have been even more heavy-handed to remove datacarriersize entirely.
The reason for changing the default isn’t just that OP_RETURN is already used, and data storage through other means is already possible (including through ways that are cheaper than through OP_RETURN); it is that attempting to address this at the relay level is not more than a mild discouragement
According to the data, nonstandard opreturns are 99% less popular than standard ones. Calling this “mild discouragement” might be the understatement of the century.
and given enough incentives to bypass it (as we’ve seen exist)
We’ve seen a few nonstandard transactions slip through here and there, but brc20 and runes were the worst recent spam attacks and both were built on standard transactions, not nonstandard ones. It is very doubtful that a token Ponzi launching on top of a nonstandard transaction type would be very popular.
is harmful on itself, both for the ecosystem at large, and for individual node runners, in addition to being ineffective.
We’ve already established that they are effective for their purpose, which is severe ratelimiting, but let’s hear your reasoning for why they are harmful.
The reason it is harmful for the ecosystem at large is mining centralization. Given enough demand for transactions that the network of nodes shuns (for whatever reason), large miners are incentivized to develop means for users and companies to submit these shunned transactions directly to them (this is already happening to some extent).
This is true only if mining nodes largely disagree with the rest of the network about which transaction formats are harmful. The only time the miners should win this disagreement is if the node network is being sybiled by an entity attempting to censor. The rest of the time, miners should heed the will of the supermajority of users, and miners should be considered hostile entities if they continue mining large volumes of transactions the rest of the network has deemed abusive.
If these “out-of-band translation relay rails” end up becoming economically relevant enough (through the out-of-band fees they involve) that miners not using them become uncompetitive, the ecosystem has a huge problem, far bigger than some temporary JPEG hype drivel: the inability for new small miners to enter the ecosystem (because who would bother sending transactions to a tiny miner)
This seems to be a point of contention between the core and knots sides of this debate; personally I am skeptical that this is as big of a problem as you seem to, but I assume you have data/reasoning to back this up, and I would be interested in seeing it.
The question is: how big of a mining centralization risk is opreturn being left at 80 bytes, and why wasn’t the opreturn filter a mining centralization risk the entire decade it’s been in existence? Why suddenly now is there a huge mining centralization risk? Are there other filters that are mining centralization risks? Perhaps limits on future script versions or transaction size? If opreturn can suddenly become a mining centralization risk after a decade of minding its own business and doing exactly what it’s supposed to be doing, what other filters might do the same thing?
You seem to think that the risk is bad enough to risk bitcoin ceasing to be money by arbitrary data making bitcoin difficult or impossible to use for payments, so it must indeed be a large risk. I have repeatedly asked core devs and other supporters what problem/risk PR 32406 is attempting to solve[7], and no one seems to have an answer other than “Citrea is going to put 64 bytes into the utxoset”, which is of course incoherent.
especially anonymously (the best protection the ecosystem has long term against miner censorship).
This can be done by identifying miners by their bitcoin addresses; see memcooler[5] and Ocean mining’s user account model, plus tracking which blocks were previously mined to which addresses, for how this could be done.
In addition, it incentives the development of one or a few centralized “payment submission network” companies that all big transaction creators and miners contract with (something we’ve seen in other blockchains), imposing a large censorship risk on this company, and making the entire goal of decentralization a shim of what it was supposed to be.
I’m curious what would stop this from happening if the government decided to sybil the bitcoin mempool relay network in order to attempt to censor certain individuals from transacting. You seem to suggest that direct miner submission schemes are *always* a bad thing, but it seems to me they could come in handy if there are ever any *real* censorship attempts.
The reason it is harmful for individual node runners is that the entire point of participating in transaction relay is having a reliable view of what transactions will be mined in the future
You appear to be forgetting that mempool relay’s *primary* purpose is to relay payments to miners. Most noderunners I know are proud of providing this valuable service to the bitcoin network. This is why the suggestion by some core devs to “just run blocksonly” is confusing.
for at least these reasons: For performing decentralized fee estimation (avoiding the need for centralized services for this).
Decentralized fee estimation works just fine without looking at the mempool. It is only necessary to look at the mempool if your goal is to get into the *very next block*. Since nobody has this need now that we have Lightning, I think it is perfectly acceptable to point users to centralized fee estimation services in the rare case where this is needed, at least until we have a way to retain transactions just for fee estimation (as we do for compact block reconstruction).
For accelerating relay of blocks. When a node already has (most, or ideally all) transactions that are included in a block downloaded and/or validated, it does not need to redo those things when transactions actually appear in a block. The BIP152 compact blocks protocol relies on this principle. The faster the node network can propagate blocks through the network, the more it reduces the benefit of large miners over small miners (this is related to selfish mining), contributing to decentralization by not hurting new small miners entering the market.
Doesn’t the risk of having a spam-filled block orphaned because of slow propagation cancel out the risk that the miner will [accidentally] perform a selfish mining attack? This is another place where I’d love to see some actual numbers.
Also, blockreconstructionextratxn helps here.
When miners accept transactions that a node shunned, the node is still required to download, process, validate, and store its result
Yes of course, but as the opreturn filter shows, if enough nodes are filtering, there is a 99% reduction in confirmed spam, so eventually the tradeoff is worth it
forgoing any benefits related to moral stance or resource usage the shunning might have had in the first place.
That is a bold claim; again, I would love to see numbers that show how much an individual node runner is hurting himself by not relaying certain transactions… my hunch is that it doesn’t hurt much at all. I’ve been running Lightning on Knots for a long time and haven’t noticed any issues.
Of course, nodes are in no way required to participate in transaction relay. They can use whatever policy they like, including not relaying transactions at all (the -blockonly setting), if they are uninterested in having a reliable view of future transactions.
Yeah, and if they are also uninterested in helping bitcoin function as a payment network…
I also hear the argument “Blocks are empty” so Miners need generate revenue. To which I also respond; Bitcoin mining is a free market and the difficulty adjustment helps miners set their output accordingly to balance their electricity bill. They could partially set their output off/on.
Miners have huge capital investments in their hardware that needs to be paid off, the actual electricity costs of running the miners are only part of their bill. In the long term you’re right of course that miners can and will shut down if they are unprofitable, and this will result in the difficulty compensating for it, making costs lower for the remaining miners. But even then, those remaining miners in the new equilibrium will prefer earning more fees over less fees!
Yes, and if everyone is filtering the same set of transactions, then no miner has an advantage here…
And if people are willing to pay those, for whatever reasons, including ones you and I dislike, they’ll find ways to do so.
Yes, and miners who include these transactions are hostile and as such will have additional costs, and there will be 99% fewer abusive transactions if we filter aggressively enough (again, see opreturn data)
So is this changed being pushed by people who want to put a storage business model on top of bitcoin, like the altcoins do ? What does will affect Node runners (like me) who don’t want to store dumb JPGS and possible illicit material on their hard drives.
Speaking for myself, I hope you believe me when I say that is not the motivation at all. I think these use cases are temporary hype cycles, and not rational use of blockchain space, but the market can stay irrational for a long time.
Agreed, they are temporary hype cycles, but they never stop. There is always another cycle, and our hostility to them is the primary deterrent that reduces their frequency and intensity.
However, I believe that attempts to discourage these use cases through node relay policy, in the presence of widespread evidence that miners accept these transactions anyway, are ineffective, akin to making nodes bury their heads in the sand, and ultimately harmful to the decentralization of the system at large.
I disagree with all of these claims. See above discussion.
(*) One small note however, the ecosystem does have an actual means of blocking transactions: consensus rule changes. If there is widespread agreement throughout the ecosystem that a certain class of transactions is harmful, the possibility exists in theory to adopt a consensus rule change that makes these transactions outright invalid, forcing miners to reject them (because otherwise they’d be producing invalid blocks, forgoing all revenue). This process is slow, should be used very carefully not to undermine fundamental properties (like censorship!) and is unsuitable for anything resembling a cat-and-mouse game like this, in my view.
Yes, this is the reason we should play the cat-and-mouse game at the policy level, and not at the consensus level. There is an army of thousands of noderunners who are eager to play the part of the cat. I honestly don’t see how we are going to lose against these invaders.
However, I do want to bring this up to make it clear that in the presence of widespread, fatally-harmful behavior, node runners are not entirely powerless in this matter.
A consensus change would obviously be a last resort, as it is very easy to store arbitrary data in the blockchain, even with extreme measures like p2sh^2. The mempool is where we should focus our efforts.
Sincerely,
Chris Guida
[0]: https://bitcoin.stackexchange.com/a/127903/34855
[1]: https://gnusha.org/pi/bitcoindev/CAAS2fgQyVs1fAEj+vqp8E2=FRnqsgs7VUKqALNBHNxRMDsHdVg@mail.gmail.com/
[2]: https://blog.bitmex.com/dapps-or-only-bitcoin-transactions-the-2014-debate/
[3]: https://x.com/GrassFedBitcoin/status/1931854732831977845
[4]: https://x.com/oomahq/status/1931856202511888465
[5]: https://github.com/gudnuf/memcooler
[6]: https://github.com/bitcoinknots/bitcoin/pull/119
[7]: https://x.com/cguida6/status/1965525597683060979
cc murchandamus sr_gi pwuille adam3us